
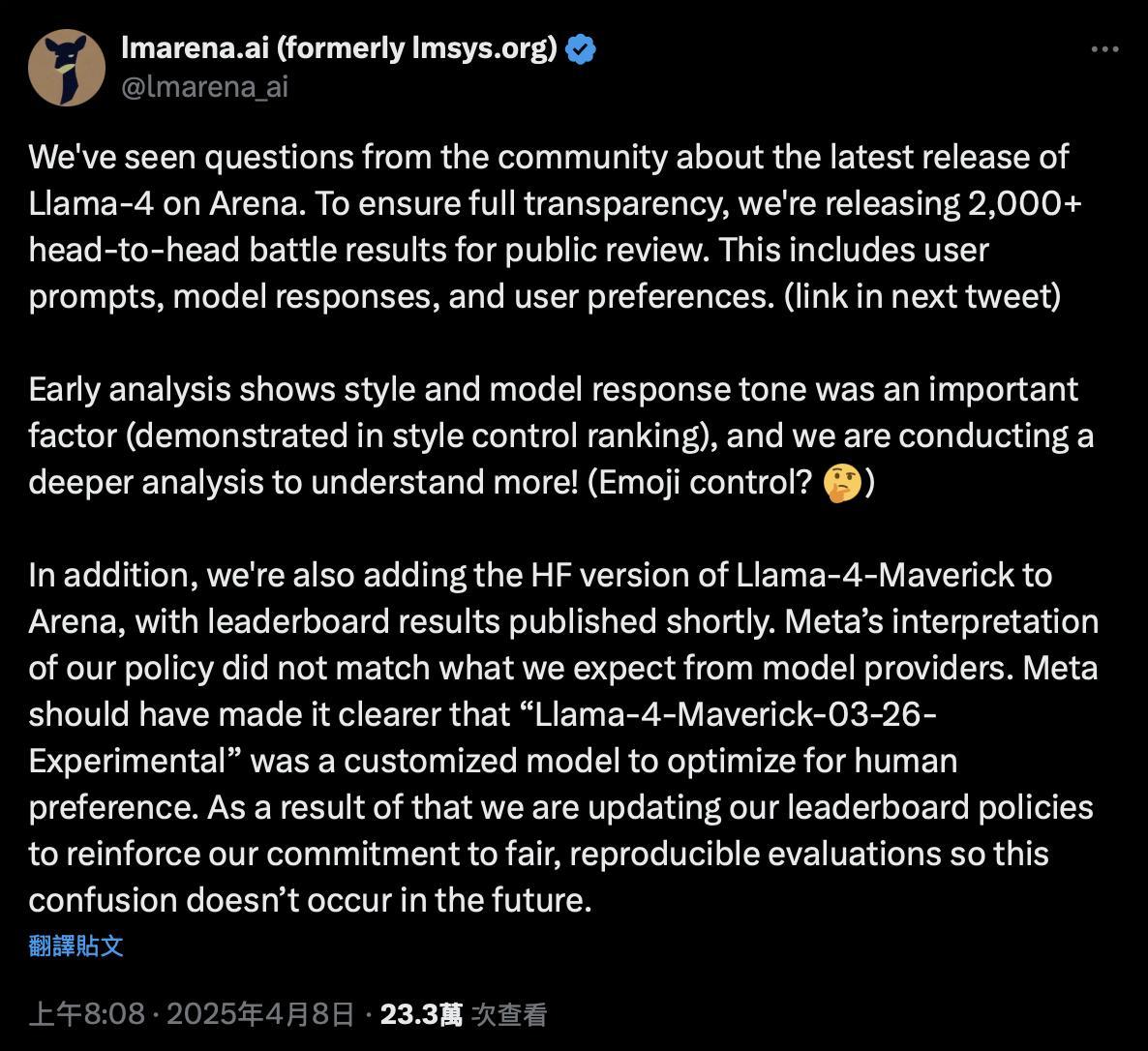
开源大模型 Llama 4 的发布引发了广泛讨论和争议。自4月5日Meta正式推出Llama 4以来,这款新模型迅速登上Chatbot Arena排行榜第二位,仅次于Google的Gemini 2.5 Pro。然而,这一排名很快引起了社区的质疑,因为被测试的版本并非Meta官方开源的正式版,而是一个未公开、定制化调优的实验模型。对此,Chatbot Arena官方发布声明,表示将公开2000多场真人对比测试的完整数据,并点名Meta,强调其应明确说明该模型为优化人类偏好的定制化版本。
Chatbot Arena由加州大学伯克利分校发起,是当前最具行业影响力的大模型评测平台之一。其核心机制是通过真人盲测的方式,让开发者和AI爱好者对不同模型的表现进行评分。这种机制使得Chatbot Arena成为最受信赖的大模型排行榜之一,直接影响了模型在媒体和开发者群体中的口碑与采纳率。
然而,Llama 4的实际表现却远未达到预期。在多个专业基准测试中,Llama 4的表现不尽如人意,甚至垫底。例如,在Aider Chat提供的Polyglot编程测试中,Maverick版本的正确率仅为16%,落后于规模更小的开源模型。许多用户在Reddit、X等社交平台上表达了失望,认为Llama 4在编程能力上存在明显不足。
面对质疑,Meta团队进行了澄清。一位参与“后训练”的成员Licheng Yu实名表示,Meta从未使用测试集进行过针对性优化,并承诺将在下一版本中改进缺陷。此外,Meta GenAI副总裁Ahmad Al-Dahle也在X平台上明确否认了在测试集上训练Llama 4的说法。
尽管如此,Llama 4的真实能力仍然受到广泛质疑。作为开源阵营的领头羊,Llama系列曾凭借Llama 2和Llama 3逐步建立起“领先、可靠”的市场认知。然而,随着DeepSeek V3/R1等新兴开源模型的崛起,Llama 4面临着前所未有的竞争压力。Meta可能因急于赶上内部设定的时间节点,未能充分测试和优化Llama 4,导致其性能不稳定。
此次事件反映了开源大模型领域竞争的加剧。为了应对DeepSeek、Qwen、Gamma等其他大模型的崛起,Meta需要重新审视自身的策略,努力恢复用户对其品牌的信任。
本文来源: iFeng科技【阅读原文】
iFeng科技【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号