
(由多段落组成):
随着人工智能技术的快速发展,各大科技公司不断推出更强大的模型。近日,OpenAI 发布了全新的 GPT-4.1 系列模型,包括 GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano。尽管这些新模型在性能上较之前的 GPT-4o 系列有了显著提升,但与谷歌的 Gemini 系列相比,仍存在一定差距。
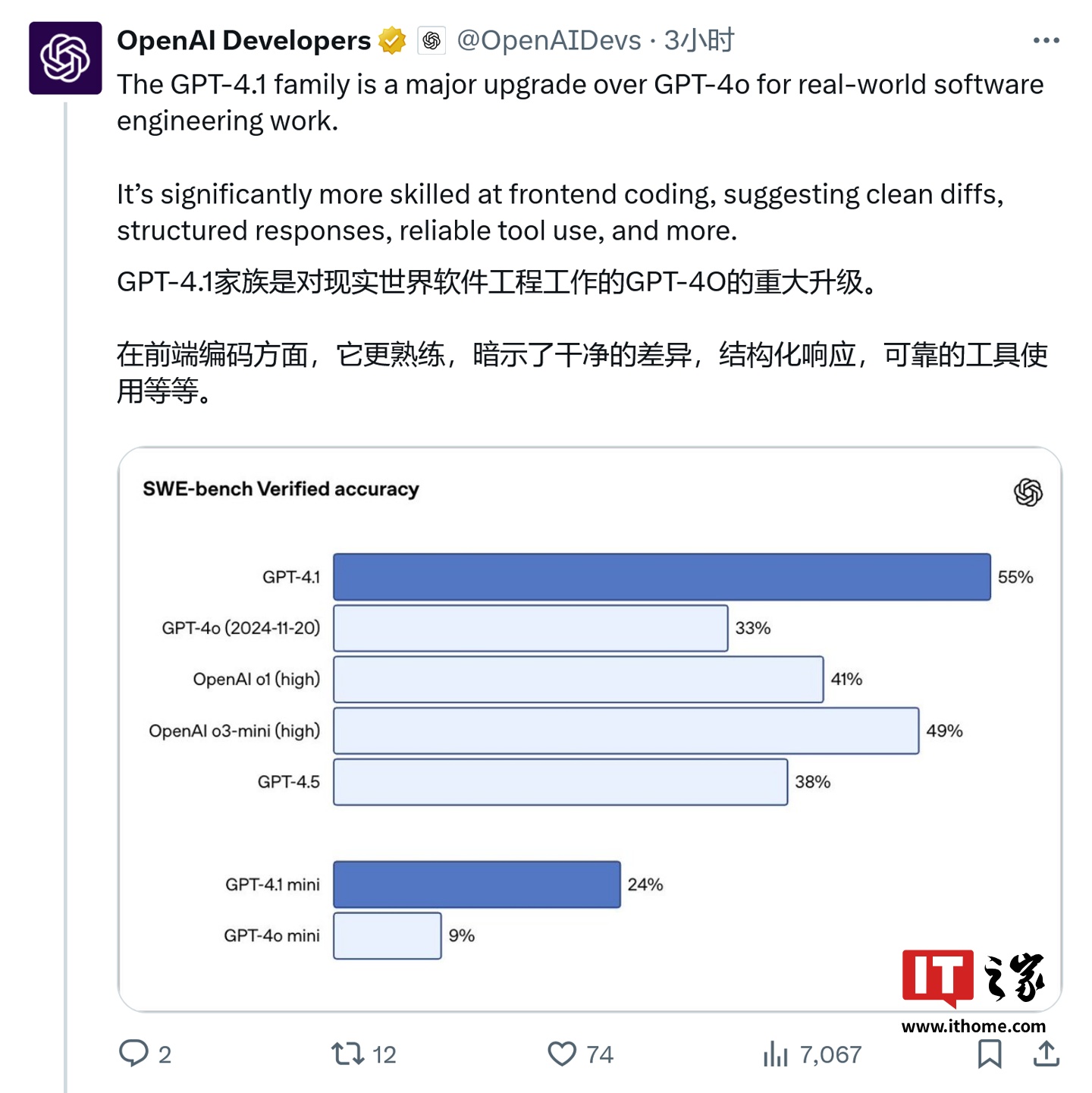
根据官方提供的数据,在编程能力方面,GPT-4.1 表现出色。例如,在 SWE-bench Verified 测试中,GPT-4.1 的得分达到了 54.6%,远超 GPT-4o 的 21.4% 和 GPT-4.5 的 26.6%。然而,多位专家测试后指出,GPT-4.1 在某些关键指标上仍落后于谷歌的 Gemini 系列。
具体来看,Stagehand(一款生产级浏览器自动化框架)发布的基准数据显示,Gemini 2.0 Flash 的错误率仅为 6.67%,精确匹配率高达 90%,同时具备更低的成本和更快的速度。相比之下,GPT-4.1 的错误率高达 16.67%,成本更是 Gemini 2.0 Flash 的 10 倍以上。
此外,哈佛大学 RNA 科学家 Pierre Bongrand 提供的数据也显示,GPT-4.1 的性价比不及 Gemini 2.0 Flash、Gemini 2.5 Pro 和 DeepSeek 等竞争对手。特别是在编码专项测试中,Aider Polyglot 的测试结果显示,GPT-4.1 的编码得分为 52%,而 Gemini 2.5 则以 73% 的成绩遥遥领先。
值得注意的是,尽管 GPT-4.1 被归类为非推理模型(non-reasoning model),但其编码能力仍然处于行业顶尖水平。这表明 OpenAI 在特定领域依然保持竞争力,但面对谷歌 Gemini 系列的强大挑战,未来还需要进一步优化和改进。
广告声明:本文中的对外跳转链接(包括但不限于超链接、二维码、口令等形式)旨在提供更多信息,节省用户甄选时间,仅供参考。IT之家所有文章均包含此声明。
本文来源: IT之家【阅读原文】
IT之家【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号