
OpenAI-o1思考替代法热度攀升!焦剑涛高徒一作提出思考偏好优化,利用大语言模型如Llama 3 8B Instruct与AlpacaEval,拓展推理任务边界——天浩吴的创新研究
OpenAI-o1思考替代法引发关注,华人学者提出思考偏好优化方法
近期,一项新的研究引起了广泛关注,该研究提出了一种名为“思考偏好优化”(Thought Preference Optimization, TPO)的方法,旨在使大型语言模型(LLM)能够根据任务的复杂度进行不同程度的“思考”,从而提高其输出质量。这一方法不仅适用于逻辑和数学推理任务,还能应用于一般的问答场景。
研究背景与意义
这项研究由华人学者Tianhao Wu及其导师焦剑涛等人共同完成。焦剑涛曾是2011年清华大学特等奖学金获得者。研究团队提出了一种新的训练方法,通过在模型中引入“思考”过程,使模型能够在给出最终答案前进行内部评估和优化,从而提高回答的质量。这种方法无需额外的人工标注数据,具有较高的实用性和推广价值。
TPO的工作原理
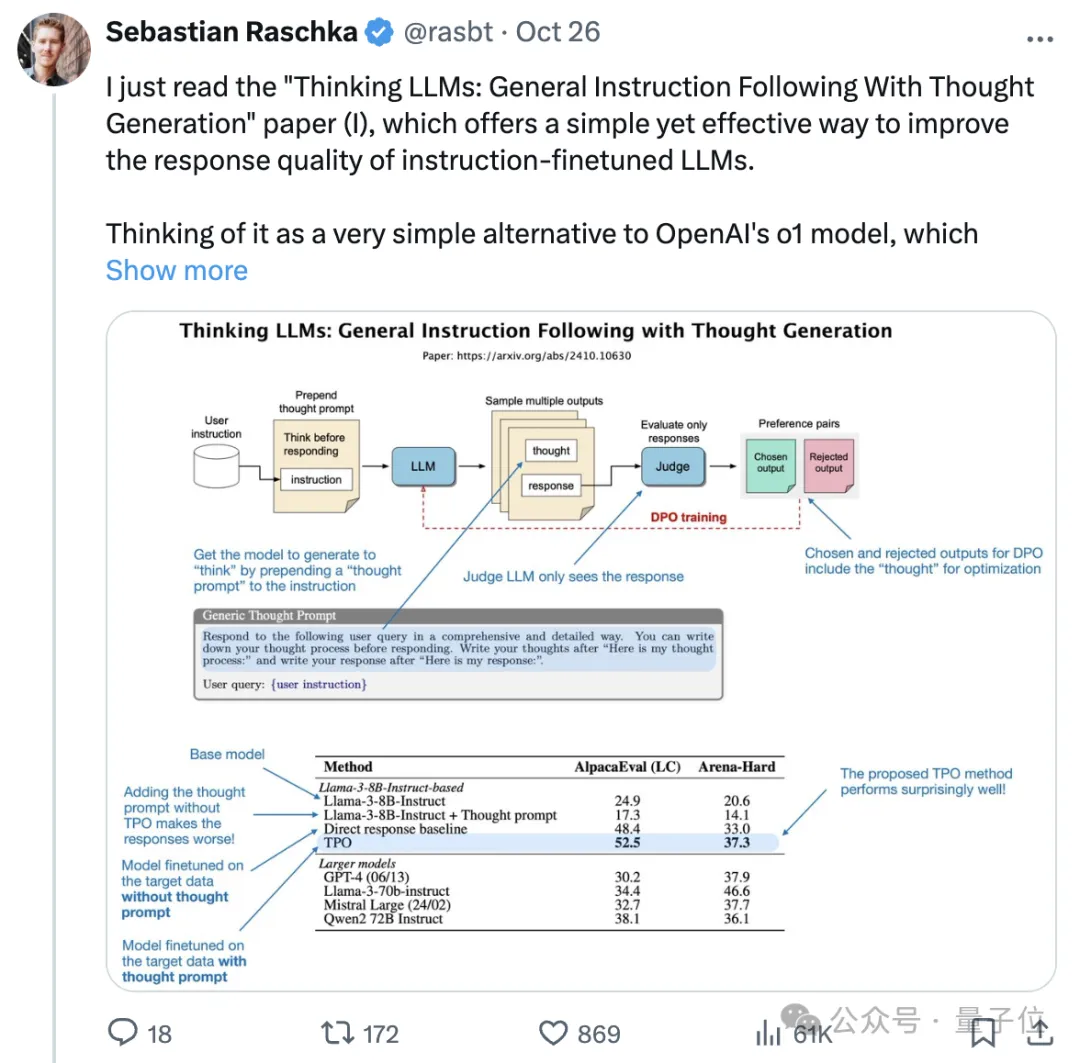
TPO的核心思想是让模型在生成最终答案之前,先生成一个“思考”过程,这个过程对用户不可见,仅作为模型内部的计算步骤。具体而言,TPO通过以下步骤实现:
1. 生成思考过程:使用提示词引导模型生成包含思考过程和最终答案的输出。提示词可以是通用的,要求模型写下思考过程;也可以是具体的,要求模型先写出草稿并进行评估。
2. 评估与选择:将生成的答案部分提供给一个评判模型进行评分。评判模型可以是对单个回答进行评分的模型,也可以是比较两个回答并选出更优者的模型。
3. 偏好对形成:根据评分结果,选择得分最高和最低的回答及其对应的思考过程,形成偏好对。
4. 直接偏好优化(DPO):使用这些偏好对进行DPO训练,使模型逐步学习到哪些思考方式能带来更好的回答。
实验结果与应用前景
实验结果显示,TPO在Llama 3 8B Instruct模型上的表现非常出色。在AlpacaEval和Arena-Hard基准测试中,TPO模型的性能分别比基线提升了约4%。即使在训练初期,带思考的模型表现不如直接回答的基线模型,但经过多轮迭代训练后,TPO模型的表现明显超过基线。
此外,研究还发现,思考不仅对推理和数学任务有帮助,在营销、健康、一般知识等非推理任务上也表现出显著的优势。模型会随着训练逐渐学会更高效的思考,思考长度也会逐渐缩短。
团队介绍
这项研究由来自Meta FAIR、加州大学伯克利分校和纽约大学的研究人员共同完成。论文的第一作者Tianhao Wu目前是加州大学伯克利分校的博士生,导师是焦剑涛和Kannan Ramchandran。Tianhao Wu的研究重点是通过强化学习改善大语言模型的指令遵循和推理能力,目标是构建能够解决多步骤推理任务的大规模模型。他还致力于开发由Agent组成的AI社会,这些Agent可以以模块化的方式连接起来,形成更强大的集体智能。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号