
在工业应用场景中,检索技术常被用来为大型语言模型(LLM)提供外部数据库的知识文档,以提高模型回答的可信度。目前,RAG(Retrieval-Augmented Generation)被认为是向 LLM 注入特定领域知识最有效的方法之一。然而,RAG 也存在一些缺点。为了确保召回包含正确信息的文档,通常每次用户查询都会检索多个文档(大约 5 到 30 个),并将这些文档整合到输入提示中。这导致输入提示的序列长度增加,从而使推理效率显著下降。具体来说,RAG 模型的首次生成标记时间(TTFT)明显高于非 RAG 模型。
为了解决这一问题,研究人员提出了《Block-Attention for Efficient RAG》这篇论文,介绍了一种块状注意力机制(Block-Attention)。该方法通过分块独立编码检索到的文档,避免了重复计算已经在其他查询中见过的文档,从而提高了在线推理效率。实验结果显示,使用 Block-Attention 的 RAG 模型与不使用 RAG 的模型具有相似的响应速度,甚至在某些情况下还能略微提升模型的准确率。
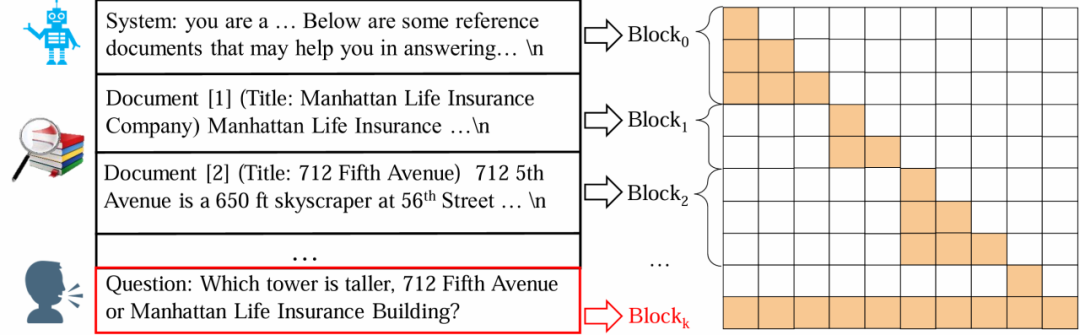
Block-Attention 的实现步骤如下:
1. 独立编码除最后一个块外的所有块。
2. 为每个块重新计算位置编码。
3. 将所有块拼接在一起,并计算最后一个块的键值状态。
直接从自注意力机制切换到块注意力机制会导致模型性能显著下降。例如,Llama3-8B 模型在四个 RAG 数据集上的平均准确率从 67.9% 下降到 48.0%。为了使模型适应块注意力机制,研究者对模型进行了微调。经过 100-1000 步的微调后,模型的平均准确率恢复至 68.4%。此外,结合 KV 缓存技术,Block-Attention 模型在极端情况下(用户输入长度为 50,prompt 总长度为 32K)的首字延时(TTFT)和首字浮点运算数(FLOPs-TFT)分别降低至自注意力模型的 1.3% 和 0.2%。
实验结果表明,Block-Attention 模型在 RAG 场景中不仅能够达到与自注意力模型相同的准确率,甚至在某些数据集上表现更好。例如,Mistral-7B-block-ft 模型在四个基准上的平均准确率从 59.6% 提升至 62.3%。位置重新编码操作对于 Block-Attention 模型的性能至关重要,去除该操作会导致性能显著下降。
在效率方面,实验结果同样令人满意。随着输入序列长度的增加,Block-Attention 模型的 TTFT 和 FLOPs-TFT 保持稳定。当输入序列长度达到 32K 时,加速效果可达到 98.7%,FLOPs-TFT 的消耗减少 99.8%。作者们总结道:“文本越长,Block-Attention 越重要”。
作者们还指出,Block-Attention 在许多场景中都有重要作用,不仅限于 RAG。由于保密原因,他们暂时无法透露在其他工业应用中的具体使用情况。他们期待社区的研究人员进一步探索 Block-Attention 的潜力,并将其应用于合适的场景。
本文来源: 机器之心【阅读原文】
机器之心【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号