
清华厦大等提出“无限长上下文”技术,100万大海捞针全绿,Llama/Qwen/MiniCPM都能上分
近日,清华大学、厦门大学等机构联合提出了一种名为LLMxMapReduce的新技术,旨在突破大模型的记忆限制,实现“无限长”上下文处理。这一创新技术通过将长文本切分为多个片段,使模型能够并行处理这些片段,并从中提取关键信息,最终汇总成完整答案。该技术不仅提升了模型处理长文本的能力,还在多个评测中表现出色。
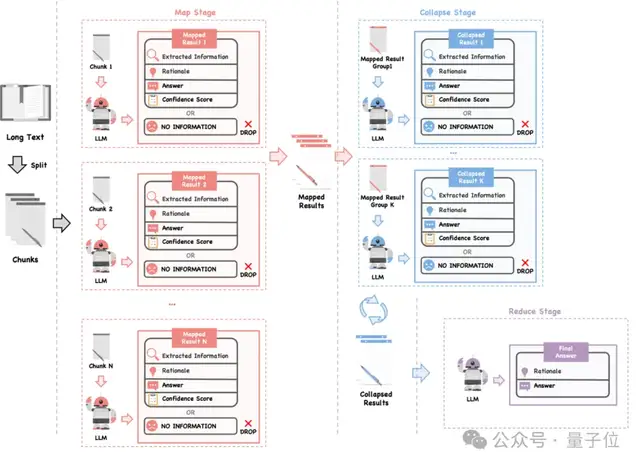
LLMxMapReduce技术原理
LLMxMapReduce技术的核心在于“分而治之”的思想,借鉴了大数据领域的MapReduce框架。具体来说,该技术将长文本切分为多个片段,每个片段可以并行处理,从而提高效率。在处理过程中,模型会从每个片段中提取关键信息,并通过结构化通信协议和上下文置信度校准机制,确保跨片段信息的准确性和一致性。这使得模型能够在处理超长文本时保持稳定的性能,减少掉分情况。
结构化通信协议和上下文置信度校准
为了处理跨片段依赖和冲突问题,LLMxMapReduce引入了结构化通信协议和上下文置信度校准机制。结构化通信协议要求模型在处理每个片段时输出包含丰富信息的结构体,这些信息在汇总阶段被用来生成最终答案。上下文置信度校准则通过统一的置信度评估标准,确保模型在处理不同片段时具有一致的置信度评估,从而更好地处理跨片段冲突。
实验结果
研究人员在InfiniteBench榜单上对LLMxMapReduce技术进行了评测,该榜单涵盖了多种长文本处理任务,最长长度超过2000k token。实验结果显示,结合LLMxMapReduce框架的Llama3-70B-Instruct模型在多个任务中取得了最高平均分数,超过了包括GPT-4在内的知名闭源和开源模型。此外,LLMxMapReduce框架还展示了较强的通用性,结合Qwen2-72B和MiniCPM3也取得了优异的成绩。
大海捞针测试
为了进一步验证LLMxMapReduce技术在处理极长文本方面的能力,研究人员进行了大海捞针测试,将文本长度扩展至1280K token。测试结果显示,采用LLMxMapReduce方法的Llama3-70B-Instruct模型能够有效处理如此长的序列,展示了其卓越的性能。此外,实验还表明,LLMxMapReduce在处理速度上也具有明显优势,优于其他同类型的分治框架。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号