
谷歌强势回归!新版Gemini跑分超o1登顶榜首,CEO:这只是开始
一水
2024-11-15 13:28:32
来源:量子位
网友:说好的碰壁呢?
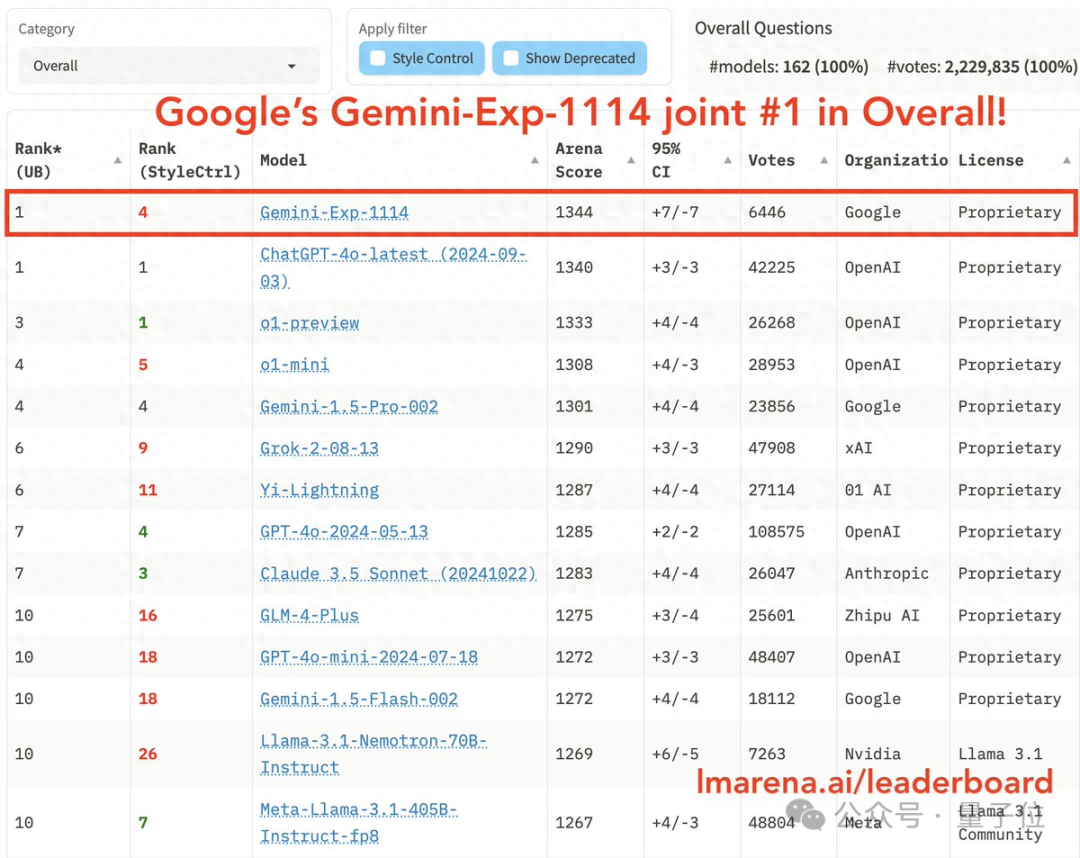
谷歌的新版Gemini模型在最新的竞技场评测中大放异彩,超越了OpenAI的o1,强势登顶总榜第一!经过6000多名网友的匿名投票,Gemini不仅在数学成绩上与o1相当,还在其他五个单项中取得了第一名。
新模型名为Gemini(Exp 1114),成绩公布后,CEO皮猜亲自到场庆祝。竞技场官方也第一时间发布了喜讯,祝贺谷歌取得这一非凡成就。
这一结果让许多人大跌眼镜。此前,谷歌被认为遇到了发展瓶颈,但这次却反手打出了一张王炸。有网友戏称,只有OpenAI立即发布满血版o1才能与之抗衡。
目前,新模型已在谷歌AI Studio上线供用户体验,官方后续也将提供API接口。网友们纷纷猜测,这是否就是传说中的Gemini 2?
性能全面突破
从总榜来看,谷歌新模型Gemini(Exp 1114)的得分提高了40多分,成功挤下了OpenAI的多个模型(包括o1-preview和GPT-4o)。如果进行一对一的较量,新Gemini在多个模型面前都有较高的胜率,如对战4o-latest的胜率为50%,对战o1-preview的胜率为56%,对战Claude-3.5-Sonnet的胜率为62%。
Gemini(Exp 1114)在单项评测中表现出色,一举拿下了六个第一,包括:
– 复杂提示(Hard Prompts):处理复杂或困难提示的能力
– 数学
– 创意写作
– 指令遵循:评估模型遵循给定指令的能力
– 长查询处理(Longer Query):处理较长查询的能力
– 多轮对话(Multi-Turn):保持多轮对话上下文连贯性的能力
最大亮点:数学能力
Gemini(Exp 1114)的最大亮点在于其数学能力,与o1模型不相上下。据OpenAI官方介绍,o1无需专门训练就能在数学奥赛中获得金牌,甚至在博士级别的科学问答中超越人类专家。然而,Gemini在编写代码方面虽然有所改进,但仍未能进入前三名,o1-mini/preview依然领先。
此外,Gemini-Exp-1114在风格控制方面表现不佳,未能进入前三名,甚至不如自家的Gemini-1.5-pro。风格控制是竞技场今年新增的功能,旨在确保模型真正解决问题的能力,而非仅仅依赖漂亮的格式和增加回答长度。
视觉能力的突破
尽管在某些方面表现一般,Gemini-Exp-1114在视觉能力上取得了突破,超越了GPT-4o。总体来看,谷歌此次的反超令人意外。
用户体验反馈
目前,Gemini-Exp-1114已上线谷歌AI Studio,用户可以进行体验。官方计划后续提供API接口。用户反馈不一,主要发现如下:
– 拥有32k上下文窗口
– 回答知识截止日期为2023年4月,但回答结果有所不同
– 加入了思维链
其中,32k上下文窗口受到不少用户的吐槽,认为相比200万上下文窗口的Gemini 1.5有所退步。谷歌AI Studio负责人回应称将尽快改进。
用户反馈显示,Gemini-Exp-1114在数学能力上表现出色,正确回答了2024美国数学奥林匹克预选赛II 1-8题。在编码方面,尽管相对薄弱,但也有人首次尝试即成功。然而,Gemini-Exp-1114在一些基础问题上仍有失误,如物理问题和简单的数字比较。
是否为Gemini 2?
关于Gemini-Exp-1114是否为传说中的Gemini 2,用户意见不一。部分用户认为它并未解决旧版1.5 Pro的一些问题,可能是谷歌推迟发布更大模型的一种策略。CEO皮猜的表态似乎也在为此做铺垫,暗示这只是开始。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号