
引言
随着人工智能技术的迅猛发展,确保语言模型生成的真实性成为了一项重要挑战。目前,尽管前沿的大语言模型(LLM)在许多任务上表现出色,但它们有时会产生错误或缺乏证据支持的输出,这被称为“幻觉”问题。这种问题严重限制了大语言模型在实际应用中的广泛使用。因此,评估大语言模型的真实性能力变得尤为重要。
新的评估基准
近日,淘宝天猫集团的研究者们提出了一种新的中文简短问答(Chinese SimpleQA)基准,这是首个全面评估大语言模型中文真实性能力的基准。该基准具有“中文、多样性、高质量、静态、易于评估”五大特点,旨在帮助开发者更好地理解其模型在中文环境下的表现,并促进基础模型的发展。
基准特点
1. 中文特性:专注于中文语言,能够全面评估现有大语言模型在中文语境下的真实性能力。
2. 多样性:涵盖6个主要主题,包括“中国文化”、“人文”、“工程、技术与应用科学”、“生活、艺术与文化”、“社会”和“自然科学”,共99个子主题。
3. 高质量:实施了全面且严格的质量控制流程,确保基准的准确性和可靠性。
4. 静态性:参考答案固定,不会随时间改变,保持基准的长期有效性。
5. 易于评估:问题和答案简短,便于通过现有大语言模型(如OpenAI API)进行快速评估。
数据收集与验证
中文简短问答的数据收集过程包括自动构建和人工验证两个阶段。自动阶段涉及提取和过滤相关知识、自动生成问题-答案对、使用大语言模型验证这些对、执行检索增强生成(RAG)验证,以及进行难度筛选。人工验证阶段则通过两名注释者独立评估每个问题,确保其符合预定义的标准,并使用权威来源(如维基百科、百度百科)进行验证。
实验结果
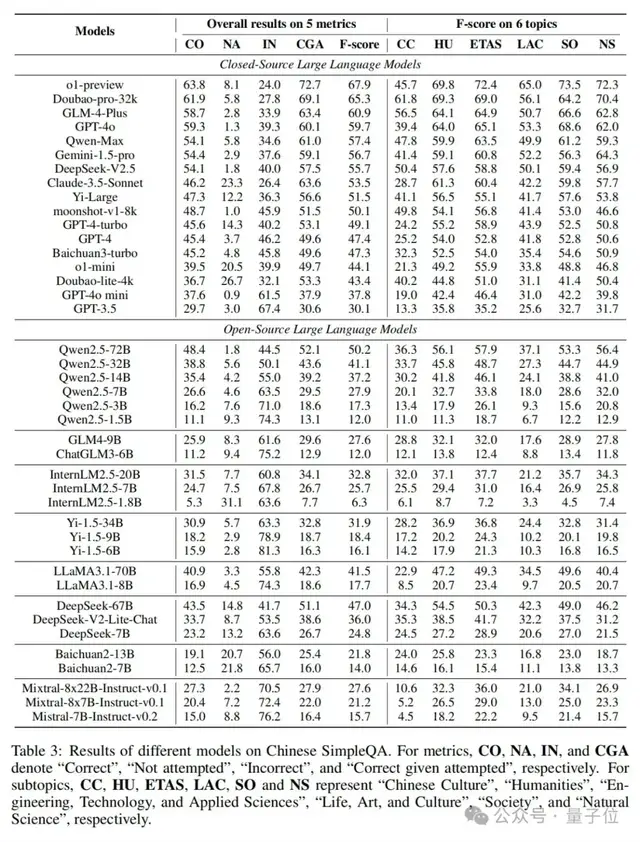
研究人员在中文简短问答上对40多个大语言模型进行了全面评估,得出了一些重要的发现:
1. 挑战性:只有o1-preview和Doubao-pro-32k达到了及格分数(分别为63.8%和61.9%),许多闭源和开源大语言模型仍有很大改进空间。
2. 模型规模:模型越大,性能越好。例如,Qwen2.5系列、InternLM系列、Yi-1.5系列等大模型的表现明显优于小模型。
3. 校准效果:大模型通常比小模型更校准,例如o1-preview比o1-mini更校准,GPT-4o比GPT-4o-mini更校准。
4. RAG策略:引入RAG策略后,不同大语言模型之间的性能差距显著缩小,例如GPT-4o和Qwen2.5-3B的性能差距从42.4%缩小到9.3%。
5. 对齐代价:对齐或后训练策略通常会降低语言模型的真实性,例如Baichuan2系列模型的F分数分别降低了47%和28%。
子主题分析
不同大语言模型在不同子主题上的表现存在显著差异。例如,中文社区模型(如Doubao-pro-32k、GLM-4-Plus)在“中国文化”子主题上明显优于GPT或o1系列模型,而在科学相关子主题上,o1系列模型表现更好。
与SimpleQA的比较
中文简短问答与SimpleQA相比,模型在不同语言数据集上的表现存在显著差异。例如,Doubao-pro-32k在中文简短问答上的排名显著提高,从第12位上升到第2位,而GPT-4的排名则从第3位下降到第9位。这强调了在不同语言环境下评估模型的重要性。
结论
中文简短问答基准的提出,填补了中文语言模型真实性评估领域的空白,为开发者提供了一个有效的工具。未来,研究者将进一步探索提高大语言模型真实性的方法,并将中文简短问答扩展到多语言和多模态设置。
 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号