
Ilya Sutskever 在 NeurIPS 2024 的最新演讲
继李飞飞、Bengio 和何恺明之后,Ilya Sutskever 在 NeurIPS 2024 大会上发表了最新的演讲。尽管演讲时长仅约 15 分钟,但丰富且引人深思。Ilya 在演讲中提出了一些重要的观点,例如:“我们所熟知的预训练即将终结。”对于未来,Ilya 预测:“接下来将是超级智能:代理、推理、理解和自我意识。”
回顾十年技术发展
Ilya 以一张十年前的 PPT 截图开始了他的演讲,那时深度学习还处于探索阶段。2014 年在蒙特利尔,他和他的团队(包括 Oriol Vinyals 和 Quoc Le)首次提出了深度学习的理念。当时的 PPT 揭示了他们工作的核心:自回归模型、大型神经网络和大数据集的结合。这些元素在当时并不被广泛看好,但现在已成为人工智能领域的重要基础。
Ilya 强调了深度学习的一个重要假设:如果有一个 10 层的大型神经网络,它就能在一秒钟内完成人类能做的任何事情。这一假设基于人工神经元与生物神经元的相似性,推动了深度学习的研究,并实现了许多当时看似大胆的目标。
此外,Ilya 还介绍了自回归模型的核心思想:通过训练模型预测序列中的下一个 token,当模型预测得足够准确时,它就能捕捉到整个序列的正确分布。这一思想为后来的语言模型奠定了基础,尤其是在自然语言处理领域的应用。
当然,也有“押错”的技术。LSTM(长短期记忆网络)就是一个例子。尽管 LSTM 在当时为神经网络提供了强大的能力,但其复杂性和局限性也很明显。另一个例子是并行化(parallelization),尽管现在我们知道 pipeline 并不是一个好主意,但在当时,通过在每个 GPU 上运行一层网络,实现了 3.5 倍的速度提升。
规模假设的重要性
Ilya 认为,规模假设是深度学习成功的关键。这一假设表明,如果你有一个非常大的数据集,并训练一个足够大的神经网络,那么成功几乎是可预见的。这个观点已经成为今天深度学习领域的核心法则。Ilya 进一步阐述了连接主义的思想,认为人工神经元与生物神经元之间的相似性给了我们信心,即使不完全模仿人脑的结构,巨大的神经网络也能完成与人类相似的任务。
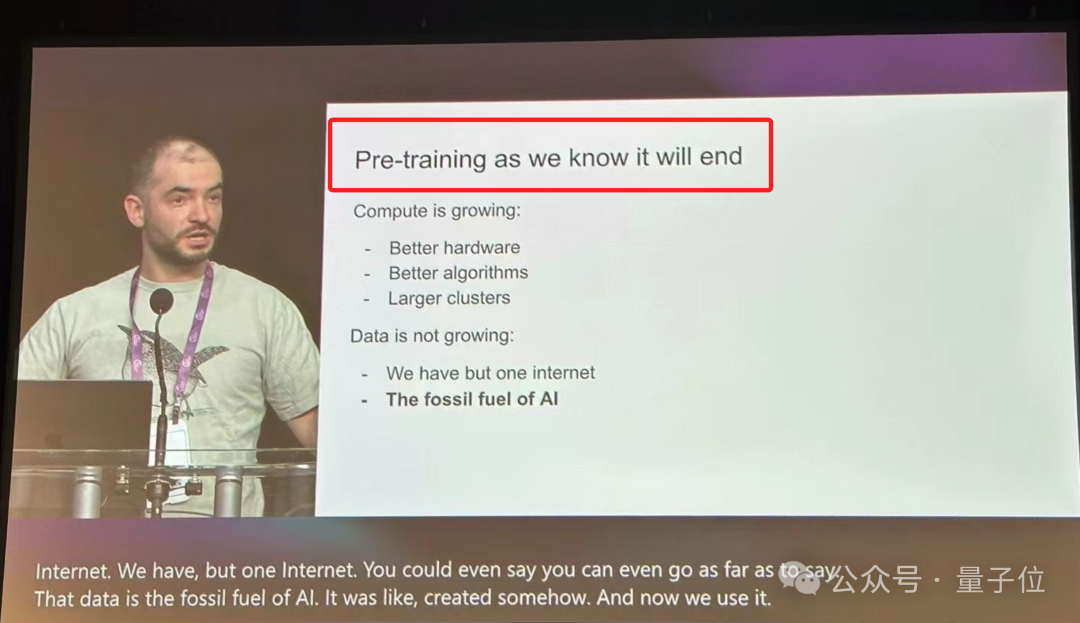
预训练时代的终结
基于上述技术的发展,我们迎来了预训练的时代。预训练是推动所有进步的动力,包括大型神经网络和大规模数据集。然而,Ilya 预测,尽管计算能力在不断增长,硬件和算法的进步使得神经网络的训练效率得到了提升,但数据的增长已接近瓶颈。他认为,数据是 AI 的“化石燃料”,随着全球数据的限制,未来人工智能将面临数据瓶颈。尽管当前我们仍然可以使用现有数据进行有效训练,但这一增长趋势终将放缓,预训练的时代也将逐步结束。
超级智能的未来
在谈到未来的发展方向时,Ilya 提到了“Agent”和“合成数据”的概念。许多专家认为,Agent 系统和合成数据将是突破预训练瓶颈的关键。Agent 系统指的是能够自主推理和决策的人工智能,而合成数据则可以通过模拟环境创造新的数据,弥补现实世界数据的不足。
Ilya 还引用了一个生物学上的例子,展示了哺乳动物身体与大脑大小的关系,暗示不同生物可能通过不同的“规模法则”进化出不同的智能表现。这一思想为深度学习领域的进一步扩展提供了启示,表明人工智能也许可以通过不同的方式突破目前的规模限制。
Ilya 最后谈到了超级智能的前景。他指出,虽然当前的语言模型和 AI 系统在某些任务上表现出超人类的能力,但它们在推理时仍显得不稳定和不可预测。推理越多,系统变得越不可预测,这一点在一些复杂任务中表现得尤为突出。他还提到,目前的 AI 系统还不能真正理解和推理,虽然它们能模拟人类的直觉,但未来的 AI 将会在推理和决策方面展现出更加不可预测的能力。Ilya 进一步推测,未来的 AI 将不仅仅是执行任务的工具,而会发展成“Agent”,能够自主进行推理和决策,甚至可能具备某种形式的自我意识。这将是一个质的飞跃,AI 将不再是人类的延伸,而是一个具有独立智能的存在。
本文来源: IT之家【阅读原文】
IT之家【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号