
CogAgent-9B-20241220:智能体任务的开源模型
智谱技术团队于12月26日宣布,正式开源了专为智能体任务设计的基座模型——CogAgent-9B-20241220。该模型基于GLM-4V-9B训练而成,旨在通过屏幕截图输入,预测用户在图形用户界面(GUI)上的下一步操作。这一特性使得CogAgent能够广泛应用于个人电脑、手机和车机设备等各类GUI交互场景。
模型升级亮点
相较于2023年12月发布的首版CogAgent模型,CogAgent-9B-20241220在多个方面实现了显著提升:
1. GUI感知与推理预测准确性:新版本在理解和预测用户意图方面更加精准。
2. 动作空间完善性:支持更丰富的基础动作和高级拟人行为。
3. 任务普适性和泛化性:适用于更多种类的任务,且具有更强的适应能力。
4. 多语言支持:支持中英文双语的屏幕截图和语言交互,增强了跨语言应用的灵活性。
输入输出特点
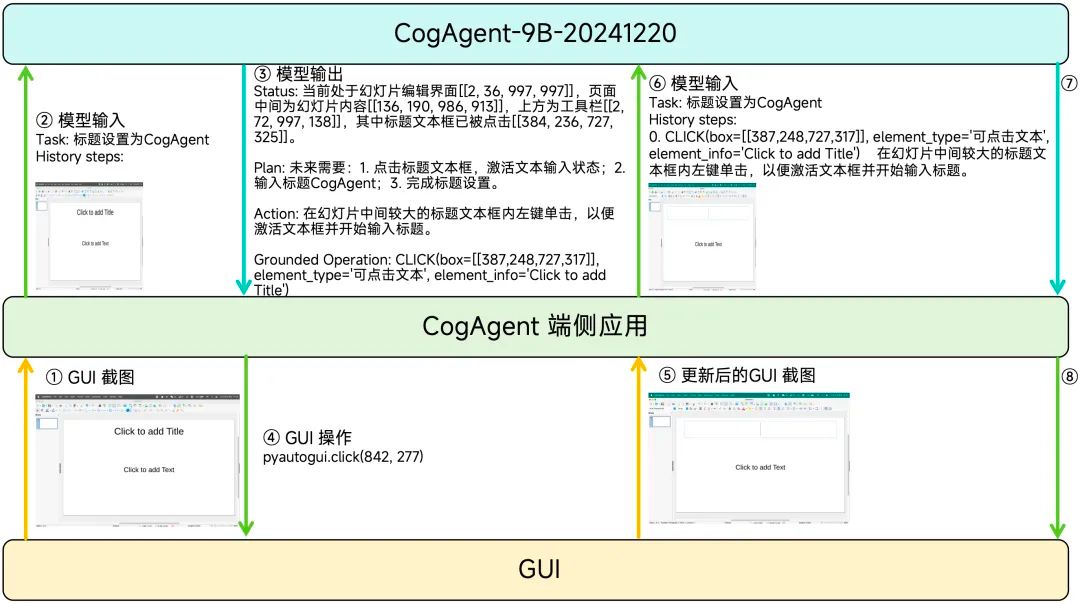
CogAgent的输入仅包含三部分:
– 用户的自然语言指令
– 已执行的历史动作记录
– GUI截图
无需额外的HTML文本表征或元素标签信息。其输出则涵盖四个方面:
– 思考过程:显式输出对GUI截图的理解及下一步操作的计划。
– 自然语言描述:以自然语言形式描述下一步动作,并将其加入历史操作记录。
– 结构化描述:以类似函数调用的形式描述下一步操作及其参数,便于解析和执行。
– 敏感性判断:区分“一般操作”和“敏感操作”,确保重要操作的安全性。
性能测试与对比
CogAgent-9B-20241220在多个数据集上进行了测试,包括Screenspot、OmniAct、CogAgentBench-basic-cn和OSWorld。与GPT-4o-20240806、Claude-3.5-Sonnet、Qwen2-VL、ShowUI和SeeClick等模型相比,CogAgent在多个指标上表现出色,证明了其在GUI Agent领域的强大性能。
本文来源: IT之家【阅读原文】
IT之家【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号