
通过noise_step和低精度训练显著降低GPT-3算力需求,仅用20MB存储空间,这篇探讨1.58-bit模型训练及反向传播替代的分布式训练新论文引发热议
突破性技术:GPT-3存储只需20MB,算力直降97%
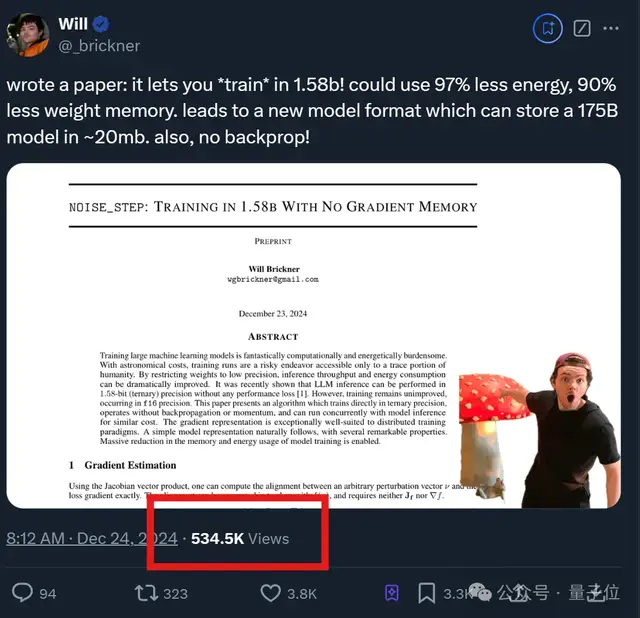
近期,一篇关于大幅降低大语言模型(LLM)训练和存储成本的新论文引起了广泛关注。这篇由机器学习研究者Will Brickner发表的论文提出了一项名为“noise_step”的新技术,能够在不损失精度的情况下,将1750亿参数的GPT-3模型压缩至仅需20MB的存储空间,并且显著减少算力消耗(下降97%)。
不依赖反向传播的新训练方法
传统的神经网络训练依赖于反向传播算法,通过逐层计算损失函数对每个权重的梯度来更新网络权重。然而,noise_step技术打破了这一传统,允许模型直接在低精度(1.58-bit)下进行训练,而无需反向传播或动量加速。这不仅减少了计算资源的需求,还大大降低了存储使用。
基于雅可比向量积的梯度估计
为了实现这一点,作者参考了《Gradients without Backpropagation》一文,引入了雅可比向量积(JVP)的方法。通过在前向传播中引入随机性,生成一个随机向量并与目标函数的梯度对齐,从而在多个随机方向上重复计算JVP,最终估计出整个梯度向量。这种方法避免了复杂的反向传播过程,使得训练更加高效。
显著降低存储需求
由于不需要存储大量的扰动向量,noise_step仅需一个种子(初始值)即可复现整个训练过程。这意味着可以大幅减少存储需求,甚至可以在一秒钟内下载一个最先进的模型。此外,该技术还支持恢复权重的历史记录,使得微调变得更加灵活和高效。
分布式训练效率提升
在分布式训练环境中,noise_step通过减少每个扰动所需的位数,显著降低了节点之间的通信量,提高了训练速度。不过,这也带来了模型泄露的风险,因为整个模型可以通过几个字节的训练步骤来传输。
实验与分享
目前,这篇论文已发布在GitHub上,感兴趣的读者可以进一步查看详细。此外,作者还提供了一个CPU实现过程的代码示例,方便大家进行实验。
参考链接
– 论文地址:[https://github.com/wbrickner/noise_step?tab=readme-ov-file](https://github.com/wbrickner/noise_step?tab=readme-ov-file)
– CPU实现过程:[https://colab.research.google.com/drive/1hXzf5xB4INzMUNTlAB8CI1V10-JV7zyg?usp=sharing](https://colab.research.google.com/drive/1hXzf5xB4INzMUNTlAB8CI1V10-JV7zyg?usp=sharing)
 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号