
机器之心学术专栏介绍
机器之心AIxiv专栏致力于发布高质量的学术和技术,涵盖全球各大高校与企业的顶级实验室研究成果。自成立以来,该专栏已报道超过2000篇,极大地促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎通过以下邮箱投稿或联系:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
浙江大学研究团队及其贡献
浙江大学软件学院硕士生二年级学生江中华,在导师张圣宇研究员的指导下,专注于大小模型端云协同计算的研究。张圣宇是浙江大学平台「百人计划」研究员,其研究方向包括大小模型端云协同计算、多媒体分析与数据挖掘。随着机器学习技术的发展,隐私保护和分布式优化的需求日益增长,联邦学习作为一种分布式机器学习技术,允许多个客户端在不共享数据的情况下协同训练模型,有效保护用户隐私。
联邦学习中的挑战与辛普森悖论
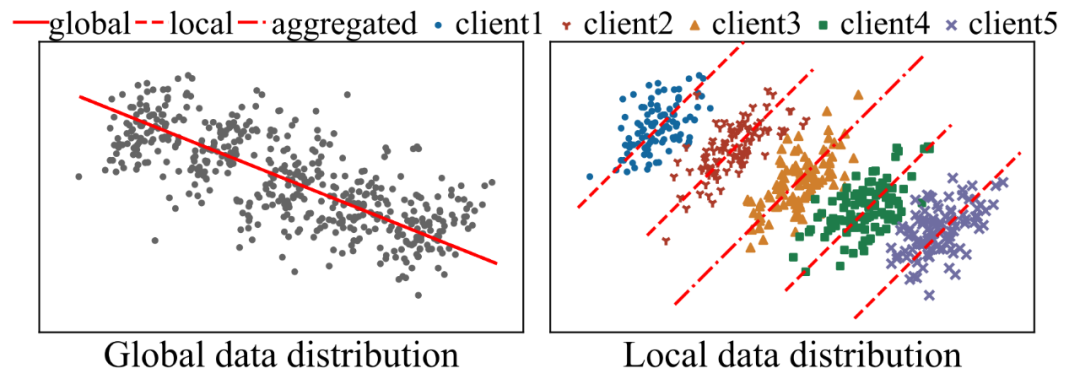
然而,联邦学习面临一个重大挑战:每个客户端的数据可能存在异质性和不平衡性(Non-IID),导致本地训练的客户模型忽视了全局数据中更广泛的模式,聚合的全局模型可能无法准确反映所有客户端的数据分布,甚至可能出现“辛普森悖论”——多端各自数据分布趋势相近,但与多端全局数据分布趋势相悖。
解决方案:FedCFA框架
为了解决这一问题,浙江大学人工智能研究所的研究团队提出了 FedCFA,一个基于反事实学习的新型联邦学习框架。FedCFA 引入了端侧反事实学习机制,通过在客户端本地生成与全局平均数据对齐的反事实样本,缓解端侧数据中存在的偏见,从而有效避免模型学习到错误的特征 – 标签关联。该研究已被 AAAI 2025 接收。
辛普森悖论的解释
辛普森悖论是一种统计现象,指当数据分成几个子组时,某些趋势或关系在每个子组中表现出一致的方向,但在整个数据集中却出现了相反的趋势。例如,在联邦学习中,某些客户端的数据中存在特定的特征 – 标签关联,而这些关联可能在全局数据中并不存在,直接将本地模型汇聚成全局模型可能会引入错误的学习结果,影响模型的准确性。
反事实学习的应用
反事实学习通过生成与现实数据不同的虚拟样本,帮助模型更好地理解数据中的因果关系,避免学习到虚假的关联。在联邦学习中,反事实学习可以帮助缓解辛普森悖论带来的问题,使全局模型更准确地反映整体数据的真实分布。
FedCFA框架的技术细节
FedCFA 框架通过在客户端生成与全局平均数据对齐的反事实样本,使得本地数据分布更接近全局分布,从而有效避免了错误的特征 – 标签关联。具体来说,FedCFA 的反事实模块选择性地替换关键特征,将全局平均数据集成到本地数据中,并构建用于模型学习的反事实正 / 负样本。此外,FedCFA 引入因子去相关损失,直接惩罚因子之间的相关系数,以实现特征之间的解耦。
实验结果
实验结果显示,FedCFA 在具有辛普森悖论的数据集上表现优异,显著提升了全局模型的精度。与传统的 FedAvg 和 FedMix 方法相比,FedCFA 通过反事实转换破坏了数据中的虚假特征 – 标签关联,使得本地数据分布更接近全局数据分布,从而提高了模型的准确性。
 机器之心【阅读原文】
机器之心【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号