
新框架Search-o1:大幅提升推理模型性能,清华人大联合出品
衡宇 白小交 发自 凹非寺
量子位 | 公众号 QbitAI
近日,清华大学和中国人民大学联手推出了一款名为「Search-o1」的新型推理模型框架。该框架在博士级别的科学问答、数学、代码能力等11项评测中表现出色,拿下了10个第一,显著提升了Qwen版o1的成绩。
# 解决推理过程中的“知识不足”问题
传统的推理模型在遇到复杂问题时,常常因为知识不足而卡壳,导致推理链中的错误传递。Search-o1通过引入自主搜索机制,有效解决了这一问题。当模型在推理过程中遇到不确定的知识点时,它会暂停推理,去搜索查找缺少的知识/资料,然后再回来继续推理,确保推理过程的连贯性和准确性。
# 自主检索增强推理能力
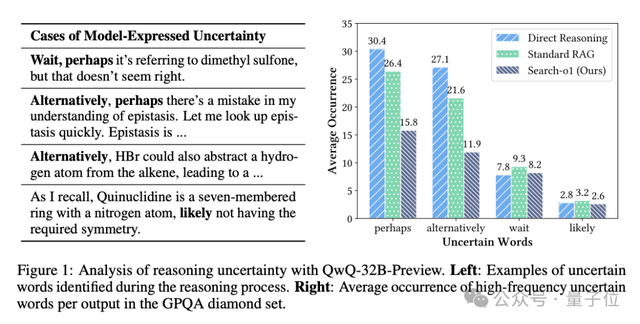
研究团队发现,类o1推理模型在处理复杂问题时,平均每个推理过程中会出现超过30次的不确定词汇,如“或许”、“可能”等。这不仅增加了推理的复杂性,还使得手动验证推理过程变得更加困难。为了解决这一问题,Search-o1结合了RAG(Retrieval-Augmented Generation)和Reason-in-Documents模块,将Agentic搜索工作流整合到推理过程中,通过自主知识检索提升大型推理模型的可靠性和适用性。
# Reason-in-Documents模块
Reason-in-Documents模块是Search-o1的核心组件之一。它独立于主推理链,基于当前搜索查询、先前推理步骤和检索文档,生成与当前推理步骤高度相关的精炼知识,并整合到推理链中。这样可以确保推理过程简洁且专注,避免冗长且不相关的信息干扰。
# Agentic RAG机制
Agentic RAG机制让模型能够在推理过程中自主决定何时检索外部知识。对于每个问题,Search-o1会先初始化推理序列,生成推理链,并在需要时生成搜索查询。当检测到特定符号后,会触发检索函数获取相关外部文档,然后由Reason-in-Documents模块处理并整合回推理链。这种机制确保模型在整个推理过程中都能获得所需的外部知识支持。
# 实验结果
为了验证Search-o1的有效性,研究人员进行了广泛的实验。结果显示,在复杂推理任务中,Search-o1在11个测试集上的表现优于原生推理和传统RAG方法,尤其在多跳QA任务上,平均准确率提升了近30%。此外,Search-o1在整体性能、物理学和生物学方面都优于人类专家,但在化学子领域稍逊一筹。
# 开源与未来展望
目前,Search-o1项目已开源,代码和论文可以在GitHub和arXiv上获取。研究团队表示,Search-o1通过有效解决模型本身知识不足的问题,增强了推理模型的可信度和实用性,为更值得信赖和更有效的智能系统铺平了道路。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号