
来自中国的AI大模型DeepSeek-R1震撼全球,成本仅为国外竞品的三十分之一
近日,中国的一家AI创业公司DeepSeek(深度求索)正式发布了其最新的大模型DeepSeek-R1。这款模型在数学、代码和自然语言推理等任务上的表现与OpenAI的o1版本相当,甚至在某些基准测试中略胜一筹。DeepSeek-R1的发布在全球AI圈引起了巨大反响。
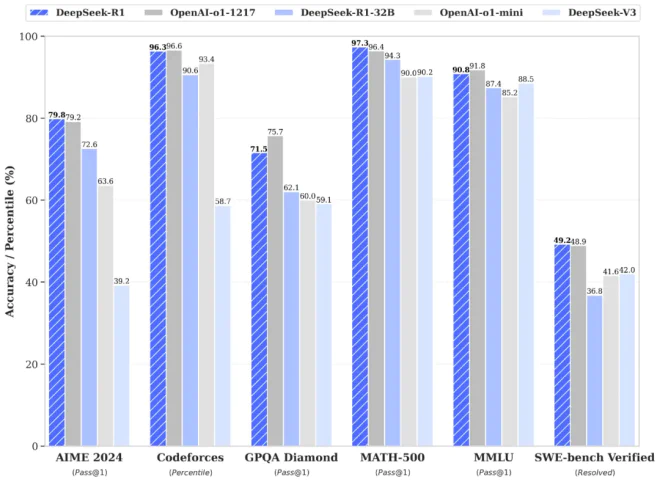
在AIME 2024数学基准测试中,DeepSeek-R1取得了79.8%的得分率,而OpenAI-o1为79.2%。在MATH-500基准测试中,DeepSeek-R1的得分率为97.3%,OpenAI-o1为96.4%。在编码任务中,DeepSeek-R1超越了96.3%的人类选手,仅略低于OpenAI-o1的96.6%。尽管性能相近或略强,但DeepSeek-R1的成本却仅为OpenAI o1的三十分之一。
DeepSeek尚未公布R1完整训练成本,但API定价显示其运行成本极低:每百万输入tokens 1元(缓存命中)/ 4元(缓存未命中),每百万输出tokens 16元。这一收费大约是OpenAI o1运行成本的三十分之一。
此外,DeepSeek-R1实现了部分开源,官方声明同步开源了模型权重,允许研究者和开发者自由使用该模型,并进行进一步的研究和开发。DeepSeek-R1支持商业用途,用户可以对模型进行任何形式的修改和衍生创作。它还开放了思维链输出,使用户可以直接看到其“思考”过程。
去年12月底,DeepSeek发布的DeepSeek-V3已经引起了一波震动。它的性能接近GPT-4o和Claude Sonnet 3.5等顶尖模型,但训练成本极低,仅花费约557.6万美元,不到其他顶尖模型训练成本的十分之一。相比之下,Llama 3.1在训练过程中使用了16,384块H100 GPU,消耗了超过6000万美元的资源。
硅谷科技界人士对DeepSeek的表现感到震惊。英伟达高级研究科学家Jim Fan表示:“DeepSeek是本年度开源大语言模型领域的最大黑马。”Scale AI创始人亚历山大·王则表达了对中国科技界追赶美国的担忧,认为这是“苦涩的教训”。
DeepSeek的技术创新也引起了广泛关注。以往的大模型依赖于监督微调(SFT)来提升推理能力,而DeepSeek-R1-Zero则直接将强化学习应用于基础模型,通过纯强化学习过程获得推理能力。这种方法避免了大量人工标注数据的工作,减少了对计算资源的需求。
DeepSeek的成功表明,高效利用资源比单纯的计算规模更重要。《自然》杂志指出,尽管美国出口管制限制中国公司获得最佳计算机芯片,DeepSeek仍成功制造了高性能大模型。这为中国AI行业带来了新的希望,也为全球AI领域带来了更多可能性。
本文来源: iFeng科技【阅读原文】
iFeng科技【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号