
杭州AI开源领域再创佳绩!阿里Qwen除夕重磅推出视觉理解模型新旗舰,涵盖多模态大模型全系列三种尺寸,7B参数量超越GPT-40-mini,尤其在视频理解能力方面表现卓越,引领行业创新潮流。
杭州在人工智能领域再次展现出强大的创新实力。2025年1月28日凌晨4点,阿里巴巴通义团队发布了全新视觉理解模型Qwen2.5-VL,并宣布全面开源。这款模型不仅支持视觉理解、Agent操作、长视频理解等功能,还推出了3B、7B和72B三种参数规模的版本。
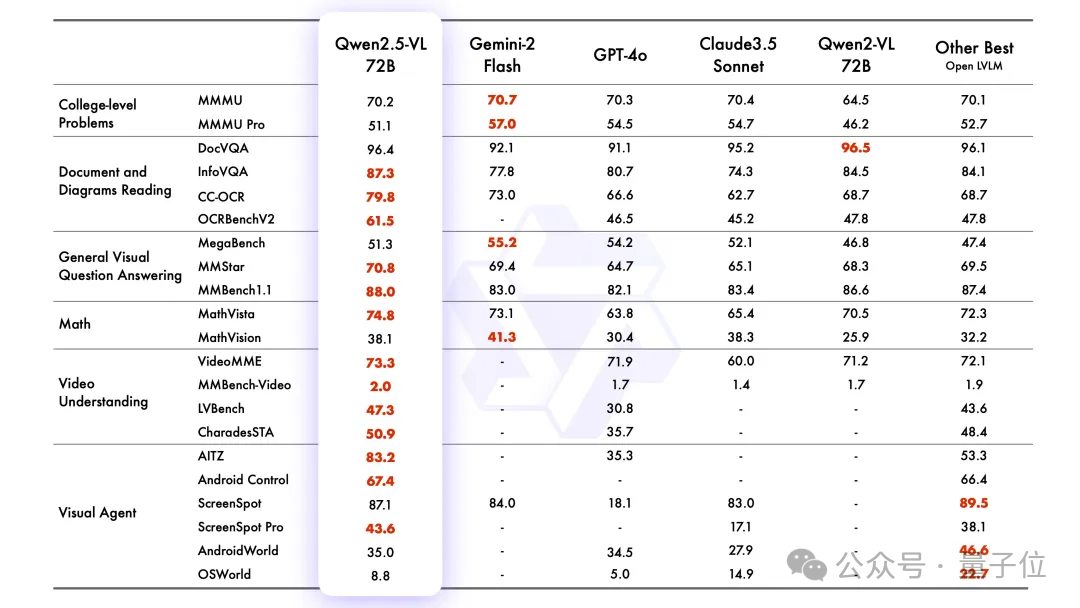
官方测试结果显示,Qwen2.5-VL系列中的7B模型(Qwen2.5-VL-7B-Instruct)在多个任务中超越了GPT-4o-mini,而72B版本则在一系列涵盖多个领域的基准测试中表现出色,包括大学水平的问题解答、数学推理、文档理解等。
此外,Qwen2.5-VL-3B被团队称为“端侧AI的潜力股”,它以较小的参数规模实现了超越此前7B模型的表现。这表明该模型在资源受限的设备上也有着广泛的应用前景。
Qwen2.5-VL的核心能力
# 1. 视觉定位能力
Qwen2.5-VL能够对通用物体进行精准定位,采用矩形框和点的方式实现层级化定位,并以JSON格式输出结果。例如,输入一张街头实拍图并要求检测所有摩托车手的位置,模型将返回坐标形式的结果。
# 2. 通用图像识别能力
相比前作Qwen2-VL,Qwen2.5-VL显著提升了其通用图像识别能力,扩大了可识别的图像类别量级,包括动植物、地标、影视IP和各类商品。
# 3. 文档解析能力
Qwen2.5-VL引入了一种新的文档解析格式——QwenVL HTML,能够准确还原文档中的版面布局,提取文本和元素位置信息。适用于杂志、论文、网页等多种场景,甚至手机截屏。
# 4. 视觉Agent操作能力
Qwen2.5-VL具备操作电脑和手机的能力,通过内在的感知、解析和推理能力执行各种任务。例如,它可以帮用户预订机票或完成其他复杂的操作。
# 5. 增强的视频理解能力
Qwen2.5-VL引入了动态帧率训练和绝对时间编码技术,支持小时级别的超长视频理解,并能快速高效地搜索具体事件。它可以在视频中捕捉关键信息,帮助用户提取重要片段。
# 6. 文字识别和理解能力
Qwen2.5-VL增强了OCR识别能力,能够在多场景、多语言和多方向下识别和定位文本,满足资质审核、金融商务等领域的智能化需求。
技术升级与未来展望
Qwen2.5-VL在时空感知和视觉编码器方面进行了多项优化。通过动态分辨率ViT和窗口注意力机制,模型不仅提高了效率,还简化了整体网络结构。未来,Qwen团队将进一步提升模型的问题解决和推理能力,整合更多模态,最终实现综合全能模型的目标。
目前,Qwen2.5-VL全系列已开源至抱抱脸和魔搭社区,用户可以通过Qwen Chat官网直接体验Qwen2.5-VL-72B-Instruct的强大功能。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号