
ICLR 2025 Spotlight:港科北邮团队利用文本控制音频技术实现空间音频生成新突破,基于BEWO-1M数据集优化双通道音频与ITD参数
ICLR 2025 Spotlight:音频生成新突破!港科大北邮团队首次通过文本控制声源方向生成音频
在影视娱乐、AR/VR等领域,通过文本控制生成多通道音频具有重要应用。香港科技大学和北京邮电大学的研究团队首次实现了这一技术突破,使生成的音频不仅符合物理世界规律,还能通过文本精确控制声源方向。
空间音频生成的重要性
人类天生具备双耳感知声音方向的能力,这种能力使得我们在日常生活中能够准确判断周围环境的声音来源。生物声学(Bioacoustics)早在20世纪就对此进行了深入研究。人耳通过以下三种方式感知声音方位:
1. ITD (耳间时间差):由于双耳之间的距离,声音到达两只耳朵的时间不同。
2. ILD (耳间声强差):声音到达两只耳朵的强度和衰减不同。
3. 生理结构:耳蜗、耳道和头骨等生理结构也影响声音感知。
技术路线与创新
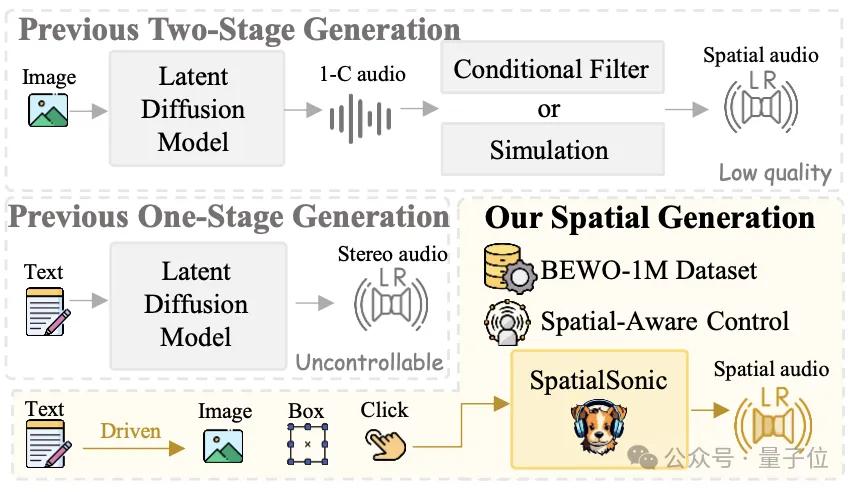
传统的Text2Audio模型只能生成单通道音频,忽略了人类对双通道音频的感知能力。为了解决这一问题,港科大北邮团队提出了一种全新的解决方案,从数据集、方法和评估指标三个方面进行创新,成功实现了可控方向的空间音频生成。
1. 双阶段方案:先生成单通道音频,再通过滤波器处理成多通道音频。但这种方法不够鲁棒,难以适应复杂场景。
2. 单阶段方案:虽然能生成立体声,但缺乏空间音频的控制能力。
3. 该研究方案:提出了一条龙解决方案,显著提升了空间音频的控制精度。
BEWO-1M 数据集
为了训练高质量的空间音频生成模型,团队构建了BEWO-1M(Both Ears Wide Open 1M)数据集,包含超过100万条音频-文本对,并支持动态声源、多声源等复杂场景。数据集分为以下几个子集:
– 单声源静态音频子集:如“猫在左边叫”。
– 单声源动态音频子集:如“直升机从左飞到右”。
– 多声源音频子集:如“左侧有雷声,右侧有狗叫”。
– 真实世界音频子集:手动标注的真实录制双通道音频。
生成方法简述
团队基于Stability AI的研究开发了双通道音频生成模型。通过finetune BEWO-1M数据集,模型能够根据自然语言提示生成指定方向的音频。然而,方向自然语言的理解仍然是一个挑战。为此,团队提出了两种改进方法:
1. 解耦空间控制和文本控制:增加空间控制引导,使用精确角度建模。
2. 利用大模型理解能力:通过推理和上下文学习获取可靠的方向信息。
评价和结果
研究团队开发了多种语义和声源方向上的评估算法,包括传统信号方法(GCC-Phat)和深度学习方法(StereoCRW)。实验结果显示,模型在文本引导的空间音频生成上表现出色。未来,团队将继续优化HRTF模拟、跨模态迁移和交互性能等方面。
项目链接
– 项目主页: [https://peiwensun2000.github.io/bewo/](https://peiwensun2000.github.io/bewo/)
– Gradio Demo (自然语言控制): [http://143.89.224.6:2436/](http://143.89.224.6:2436/)
– Gradio Demo(滑条控制): [http://143.89.224.6:2437/](http://143.89.224.6:2437/)
– Github代码: [https://github.com/PeiwenSun2000/Both-Ears-Wide-Open](https://github.com/PeiwenSun2000/Both-Ears-Wide-Open)
– Arxiv论文: [https://arxiv.org/abs/2410.10676](https://arxiv.org/abs/2410.10676)
 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号