
国内 AI 创企阶跃星辰联合吉利汽车发布两款多模态开源大模型,性能全球领先
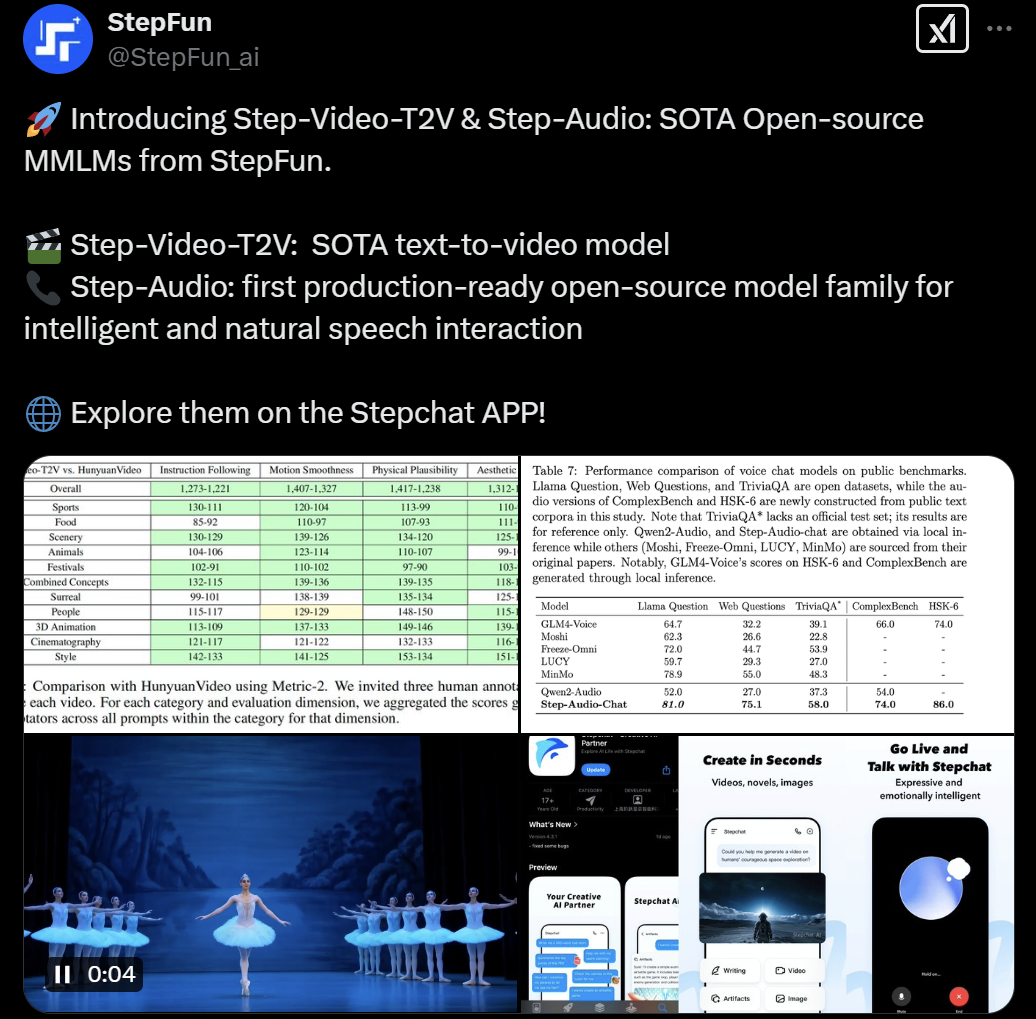
本周二,国内人工智能创业公司阶跃星辰与吉利汽车集团联合宣布,开源发布了两款多模态大模型:视频生成模型 Step-Video-T2V 和语音交互模型 Step-Audio。根据官方测评报告,Step-Video-T2V 是目前参数量最大、性能最好的开源视频生成模型。
Step-Video-T2V 模型部署及技术报告链接:
– GitHub: [https://github.com/stepfun-ai/Step-Video-T2V](https://github.com/stepfun-ai/Step-Video-T2V)
– Hugging Face: [https://huggingface.co/stepfun-ai/stepvideo-t2v](https://huggingface.co/stepfun-ai/stepvideo-t2v)
– ModelScope: [https://modelscope.cn/models/stepfun-ai/stepvideo-t2v](https://modelscope.cn/models/stepfun-ai/stepvideo-t2v)
– 技术报告: [https://arxiv.org/abs/2502.10248](https://arxiv.org/abs/2502.10248)
这款视频生成模型采用 MIT 许可协议,支持免费商用和修改开发,为开源社区带来新的技术思路。用户可以在「跃问」App 上体验这两款大模型,桌面端访问链接为 [https://yuewen.cn/videos](https://yuewen.cn/videos)。
阶跃星辰成为开源领域的新锐力量
Hugging Face 工程师 Tiezhen Wang 表示,阶跃星辰堪比 DeepSeek,其评论得到了 Hugging Face 官方的认可。GPT-J 作者 Aran Komatsuzaki 也展示了用新模型生成的视频,更多网友对国内 AI 公司对开源社区的贡献表示欢迎。
Step-Video-T2V 的卓越表现
Step-Video-T2V 在镜头调度、人物运动姿态、形象生成等方面表现出色。它能够实现多种镜头运动方式,如推、拉、摇、移、旋转等,并能处理复杂运动场景,包括芭蕾舞、空手道、羽毛球、跳水等。此外,它生成的人物形象逼真生动,细节丰富,表情自然。
技术创新与评测
Step-Video-T2V 的参数量达到 300 亿,可以单次生成 204 帧、540P 分辨率的高质量视频。研究人员设计了深度压缩变分自编码器 Video-VAE,实现了 16×16 的空间压缩比,训练和生成效率提升了 64 倍。阶跃星辰还开源了针对文生视频质量评测的基准数据集 Step-Video-T2V-Eval,包含 128 条真实用户的中文评测问题,旨在评估生成视频在多个类别上的质量。
Step-Audio:高情商且懂方言的语音交互模型
Step-Audio 能根据不同场景生成情绪、方言、语种、歌声和个性化风格的表达,使 AI 可以与用户进行自然对话。它在 LlaMA Question、Web Questions 等五大主流公开测试集上均位列第一,尤其在汉语水平考试六级 HSK-6 中表现出色,成为最懂中国话的开源语音交互大模型。
多维度贡献与未来展望
Step-Audio 的技术探索为多模态开源社区带来了五个方面的贡献:
1. 多模态理解生成一体化:单模型完成多项功能。
2. 高效合成数据链路:突破传统 TTS 数据依赖。
3. 精细语音控制:支持多种情绪和方言。
4. 扩展工具调用:集成外部工具提升表现。
5. 高情商对话与角色扮演:提供人性化回应和支持定制化角色设定。
阶跃星辰的技术路线与愿景
阶跃星辰专注于技术驱动的发展思路,不断迭代基础模型,涵盖语音识别、语音复刻及生成模型、视频理解模型等多个类别。其 AGI 路线图显示了从单模态到多模态的理解与生成统一,最终构建世界模型并实现 AGI 的目标。
本文来源: 机器之心【阅读原文】
机器之心【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号