
今天凌晨3点,阿里开源发布了全新推理模型QwQ-32B,该模型参数量为320亿,但其性能足以媲美6710亿参数的DeepSeek-R1满血版。千问团队在推文中表示:“这次,我们研究了扩展强化学习(RL)的方法,并基于我们的Qwen2.5-32B取得了一些令人印象深刻的成果。我们发现,通过持续的RL训练可以显著提高模型性能,尤其是在数学和编码任务上,并且中型模型也能实现与巨型MoE模型相媲美的效果。”
QwQ-32B已正式在Hugging Face和ModelScope平台开源,采用Apache 2.0开源协议。用户可以通过Qwen Chat直接体验新模型。此外,本地部署工具Ollama也第一时间提供了支持。
强化学习的应用与潜力
考虑到近期强化学习之父Richard Sutton与导师Andrew Barto刚刚获得图灵奖,QwQ-32B的发布显得尤为应景。博客文章《QwQ-32B: 领略强化学习之力》详细介绍了这一进展。千问团队指出,大规模强化学习在提升模型性能方面具有巨大潜力,能够超越传统的预训练和后训练方法。
例如,DeepSeek-R1通过整合冷启动数据和多阶段训练,实现了最先进的性能。而千问团队则探索了大规模强化学习对大语言模型智能的提升作用,推出了QwQ-32B。这款模型拥有320亿参数,其性能可媲美具备6710亿参数(其中370亿被激活)的DeepSeek-R1。团队表示:“这一成果突显了将强化学习应用于经过大规模预训练的强大基础模型的有效性。”
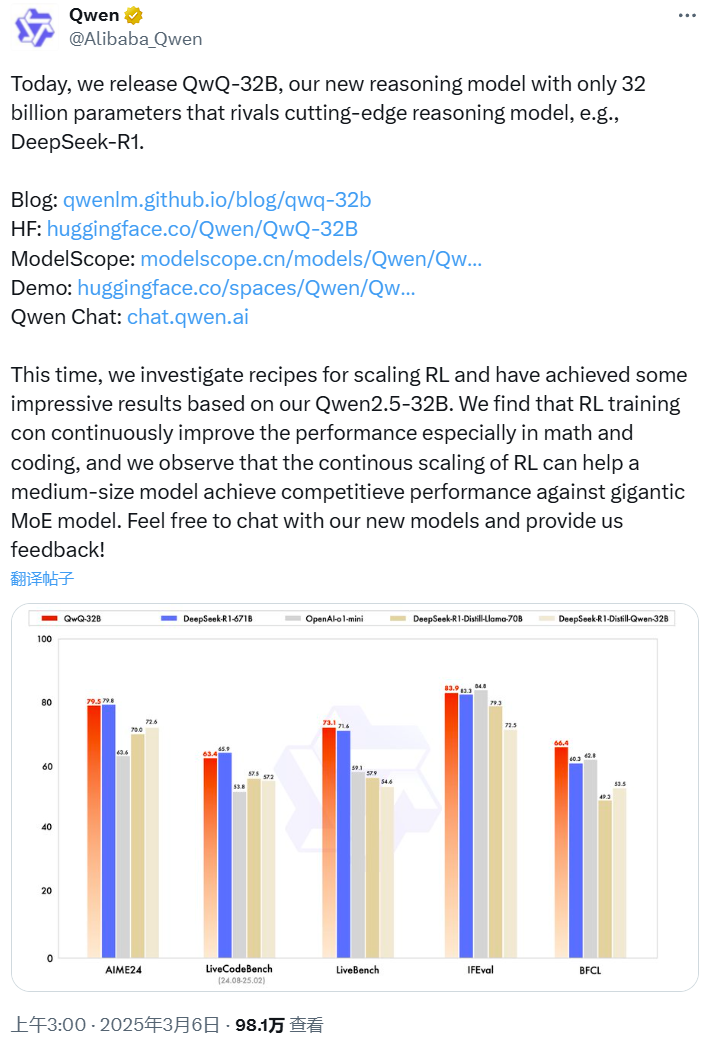
模型评估与性能对比
QwQ-32B在一系列基准测试中进行了评估,包括数学推理、编程和通用能力。结果显示,QwQ-32B在LiveBench、IFEval和BFCL等基准上表现优异,甚至略微超过了DeepSeek-R1-671B。特别是在数学和编程任务上的性能提升尤为显著。
强化学习的训练过程
QwQ-32B的大规模强化学习训练分为两个阶段。第一阶段特别针对数学和编程任务进行RL训练,通过校验生成答案的正确性和代码执行结果来提供反馈。随着训练轮次的推进,模型在这两个领域中的性能持续提升。第二阶段增加了针对通用能力的RL训练,使用通用奖励模型和一些基于规则的验证器进行训练,从而提升了其他通用能力。
API接口与未来工作
如果想通过API使用QwQ-32B,可以参考官方提供的代码示例。千问团队还分享了未来计划,他们表示:“这是Qwen在大规模强化学习以增强推理能力方面的第一步。我们相信,更强大的基础模型与依托规模化计算资源的RL相结合,将会使我们更接近实现人工通用智能(AGI)。”
用户反馈与社区反响
QwQ-32B一发布就收获了无数好评。不少读者催促我们尽快报道。有网友表示,虽然手机上还不行,但运行内存较高的Mac或许可以胜任。苹果机器学习研究者Awni Hannun也在M4 Max上成功运行了QwQ-32B,速度非常快。感兴趣的读者可以前往Qwen Chat测试QwQ-32B的预览版模型。
本文来源: 机器之心【阅读原文】
机器之心【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号