
简化DINO系列模型训练流程
最新发布的视觉预训练方法由马毅团队、微软研究院和UC伯克利等联合推出。SimDINO和SimDINOv2通过引入编码率正则化,简化了DINO和DINOv2的训练流程,并在性能上取得了显著提升。
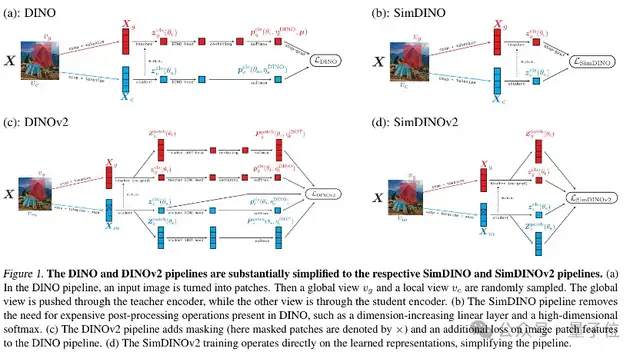
在当前的视觉预训练领域,DINO和DINOv2是顶级模型,广泛应用于多模态大模型中的视觉编码器。然而,DINO系列模型的训练过程复杂,需要精心设计的温度调度策略、中心化-锐化操作和高维原型投影层等组件。这些复杂的设置虽然能防止特征崩溃,但也使得训练过程变得异常困难。
为了解决这些问题,SimDINO和SimDINOv2应运而生。它们通过移除复杂的后处理步骤,引入编码率正则化,大幅简化了训练流程,提高了模型的鲁棒性和性能。具体改进包括:
1. 移除经验性组件:删除权重归一化的线性层、平衡操作(如中心化、锐化)以及各种超参数(如温度调度、中心化动量)。
2. 引入编码率正则化:在损失函数中添加一个简单的编码率正则化项,以防止表示崩溃。
核心方法:化繁为简
自监督学习(SSL)在处理大规模未标记图像数据方面取得了显著进展。DINO系列模型作为自监督学习的标杆选手,无需人工标注即可从海量图像中自主学习特征,并在下游任务中屡创佳绩。然而,其复杂的训练过程一直是研究人员的难题。
SimDINO团队发现,DINO中的许多复杂设计(如输出层高维投影、教师网络输出中心化-锐化操作、温度调节等)都是为了防止模型习得的表示“崩溃”。为此,他们提出了编码率正则化方法,通过在损失函数中添加显式的编码率正则项来替代这些复杂设计。
这种方法不仅简化了训练流程,还带来了几个关键优势:
– 更清晰的优化目标
– 更少的组件依赖
– 更容易的理论分析
– 更好的可扩展性
具体而言,SimDINO保留了DINO模型的EMA自蒸馏方案和多视图数据增强方法,但在对比学习方案上进行了修改。抛弃了输出层高维原型投影+交叉熵多分类,直接使用欧几里得距离/余弦相似度比较学生网络和教师网络生成的特征。加入编码率正则化项促使模型学习到更具区分性的表示,移除了教师网络输出中心化-锐化操作、温度调节等避免表示崩溃的技巧。
SimDINOv2 的进一步改进
SimDINOv2 进一步简化了DINOv2 引入的 iBOT机制。它直接使用余弦相似度监督掩码区域token与教师网络表示间的对齐,去除了Sinkhorn-Knopp centering、KoLeo正则化等复杂设计。这使得SimDINOv2的训练更加稳定,性能更强。
实验评估
为了验证SimDINO和SimDINOv2的有效性,研究团队在多个数据集和任务上进行了广泛的实验评估,包括图像分类、目标检测、语义分割以及视频对象分割。实验结果表明,SimDINO系列在计算效率、训练稳定性和下游任务性能上均优于DINO系列。
具体实验包括:
– ImageNet-1K图像分类:SimDINO和SimDINOv2在k-NN 分类和线性评估上表现优异。
– COCO val2017无监督目标检测与实例分割:采用MaskCut作为基础检测框架,主要对比了AP50、AP75和AP三个指标。
– ADE20K语义分割和DAVIS-2017视频对象分割:主要对比了mIoU和mAcc等指标,展示了SimDINO在定性特征可视化分析上的优越表现。
此外,项目论文还通过理论分析提出了关于SimDINO超参数选择的方法,确保两个项的梯度范数在优化过程中保持平衡。
研究团队
SimDINO系列由UC伯克利、忆生科技、微软研究院、香港大学等多所学校与机构的研究者共同完成。一作是UC伯克利三年级博士生吴梓阳,导师是马毅。他主要研究方向为表征学习与多模态学习,致力于通过数学与统计理论构建高效、可解释的深度学习模型。
在论文最后,SimDINO研究团队提出了几个潜在改进方向,包括探索不需要自蒸馏优化的自监督目标,简化后的框架为自监督学习的理论分析提供了更好的切入点,并将“显式化隐式设计选择”的范式推广到其他框架。
论文与代码链接
– [论文地址](https://arxiv.org/abs/2502.10385)
– [项目主页](https://robinwu218.github.io/SimDINO)
– [GitHub](https://github.com/RobinWu218/SimDINO)
 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号