
(由多段落组成)
在三维空间理解任务中,让视觉语言模型生成合理且符合物理规则的场景布局仍是一项挑战。例如,“请将这些家具合理摆放在房间中”,尽管现有模型可以识别图像中的物体并给出语义连贯的描述,但通常缺乏对三维空间结构的真实建模,难以满足基本的物理约束与功能合理性。
为解决这一问题,研究者尝试采用多智能体交互方法优化布局结果。然而,这类方法不仅计算成本高,而且容易陷入死锁。另一类方法通过构建大规模真实房间布局的描述语料,结合监督微调(Supervised Fine-Tuning, SFT)训练模型。虽然这种方式可以在一定程度上提升模型基础能力,但由于空间布局任务不存在唯一标准答案,SFT方法无法全面覆盖可能的合理解空间,限制了模型的泛化能力与生成多样性。
西北大学计算机系的研究人员提出了一个问题:是否可以通过规则驱动的强化学习策略,为视觉语言模型注入空间推理能力?三维布局任务具备强化学习适用的关键特性:不存在标准解、目标是生成符合约束的多样性解;缺乏精确标注导致监督信号稀缺;存在可程序化检测的目标函数。强化学习通过奖励函数而非依赖人工标注,引导模型在与环境交互中不断优化策略。
为此,他们提出了MetaSpatial框架。该方法首次将基于规则奖励的强化微调策略成功应用于视觉语言模型的空间布局场景中,在仅使用约50条无ground truth数据的条件下,即可显著提升模型的空间推理能力与布局生成质量。MetaSpatial构建了一套可程序化评估的奖励函数,并引入多轮布局refinement机制,引导模型逐步优化空间决策。
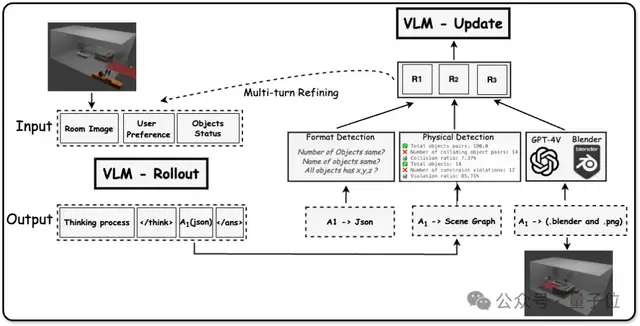
实验结果显示,MetaSpatial在多个空间生成指标上显著优于传统SFT方法。具体而言,MetaSpatial将训练3D空间推理过程建模为一个多轮决策过程。输入包括场景图像或房间结构图、几何尺寸信息、用户偏好描述和目标物体列表。模型输出分为两部分:语言化的推理过程和结构化布局JSON文件。
为了衡量布局结果的好坏,MetaSpatial构建了三级奖励信号:格式奖励检查输出JSON的完整性;物理奖励利用几何信息重建场景并计算是否存在重叠、越界等问题;主观偏好奖励通过渲染三维场景图进行审美评分。最终奖励为三者的加权组合,提供连续型反馈信号。
MetaSpatial采用multi-turn rollout策略,允许模型对布局结果进行多轮优化。每一轮的输入、输出、奖励构成一条布局轨迹,多轮优化后选取最终布局作为当前episode的结果。为实现稳定高效的策略更新,MetaSpatial引入了Group Relative Policy Optimization(GRPO),利用同一输入样本生成的多条trajectory作为一个group进行比较性学习。
实验表明,MetaSpatial能够有效提升Qwen2.5-VL的3B和7B模型的空间布局能力,尤其是7B模型的提升更为明显。强化学习训练前,模型生成的物体布局普遍混乱、错位,训练后则变得更加结构化、逼真。项目已全面开源,包含训练代码、评测流程、数据集生成脚本以及完整的数据集。
总的来说,MetaSpatial的主要贡献在于提出第一个基于强化学习的三维空间推理框架,设计多轮布局优化机制与GRPO策略,构建三重奖励体系,并验证方法的有效性。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号