
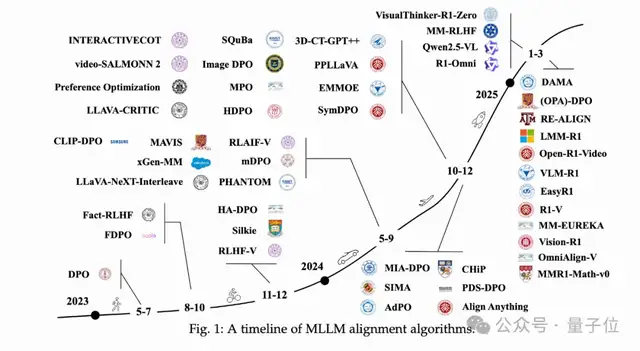
随着多模态大语言模型(MLLMs)的迅速发展,对齐算法的研究变得尤为重要。本文通过万字长文系统性回顾了多模态LLM中的对齐算法,从应用场景、数据集构建、评估方法到未来发展方向进行了全面梳理。
应用场景与代表性方法
文章介绍了多模态大语言模型的应用场景,分为三大层次:通用图像理解、多图像、视频和音频处理以及扩展应用。在通用图像理解方面,主要集中在减少幻觉并提升对话和推理能力;多图像和视频任务则通过不同的架构和训练方法来处理复杂数据,减少幻觉并提高模型能力;扩展应用包括医学、数学推理和安全系统等领域,优化模型以满足特定需求。
数据集构建
对齐数据集的构建涉及三个核心因素:数据源、模型响应和偏好注释。文章对这些因素进行了系统分析与分类,并总结了公开数据集的优势与不足。引入外部知识的数据集和依赖自我标注的数据集是两种主要类型,各有优缺点。
评估方法
针对对齐算法的评估方法,文章整理了常用的评估基准,提出了清晰的评估框架。评估维度包括通用知识、幻觉、安全性、对话能力、奖励模型表现和与人类偏好的对齐。
未来发展方向
文章提出了对齐算法发展的潜在方向,包括视觉信息的整合、LLM对齐方法的经验启示,以及MLLM作为智能体面临的挑战与机遇。
这项研究由来自多个知名机构的研究人员共同完成,由中国科学院院士谭铁牛和中国计算机学会会士王亮领衔。
本文来源: 量子位【阅读原文】
量子位【阅读原文】 © 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

互推合作 | 免责声明 | 算法备案 | AI资讯 | 关于AI部落
Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号 粤公网安备44049002000930
粤公网安备44049002000930
Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号