
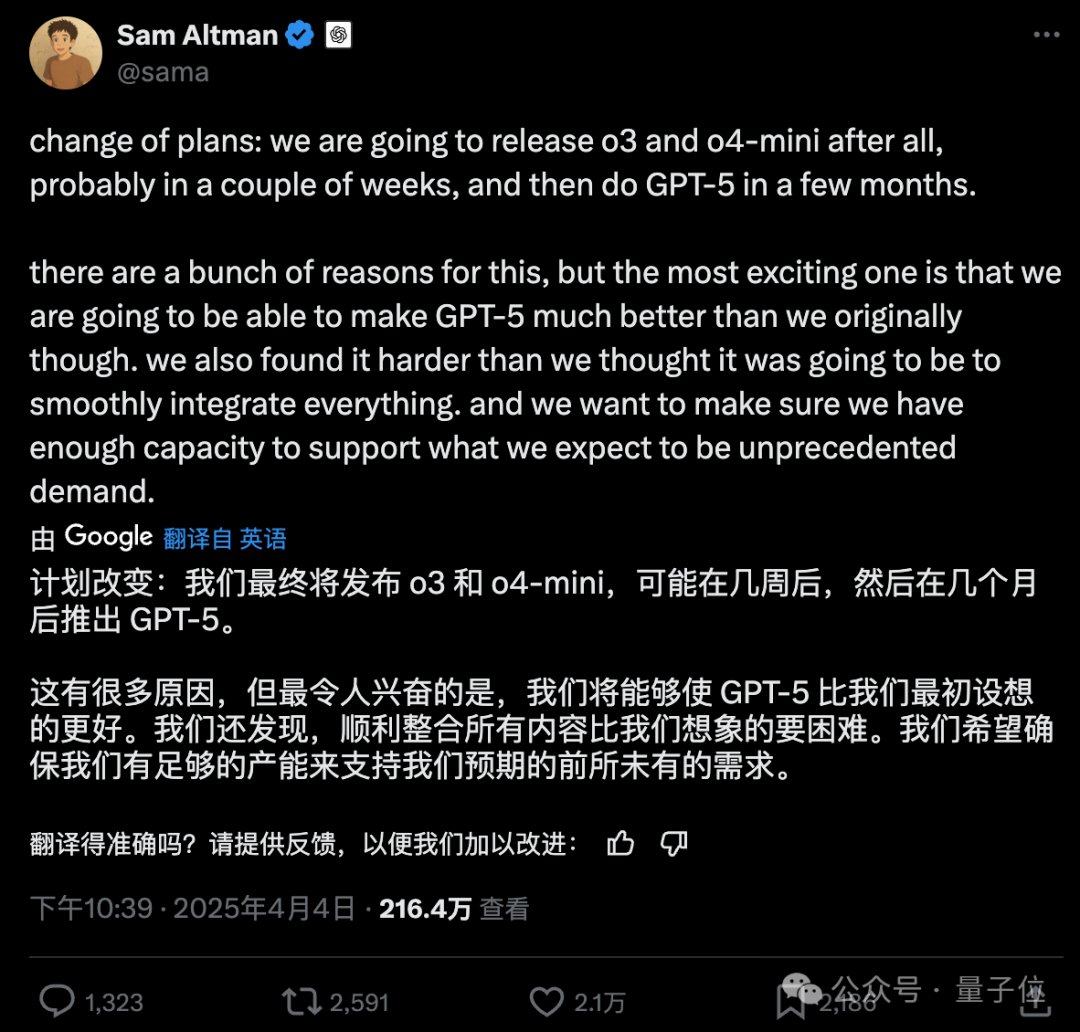
在AI领域的激烈竞争中,DeepSeek与OpenAI之间的较量愈发引人注目。最近,DeepSeek发布了一篇关于推理时Scaling Law的论文,引发了业界对R2即将发布的猜测。然而,OpenAI却突然宣布调整计划:可能会在未来几周内优先发布o3和o4-mini版本。至于备受期待的GPT-5,OpenAI表示将在几个月后推出,并且效果将超出最初的预期。
OpenAI解释了这一计划调整的原因,主要在于整合所有比预期更加困难,他们希望确保能够满足未来的需求。这也反映出当前AI市场竞争的激烈程度——DeepSeek的一举一动都会促使OpenAI迅速做出反应。
DeepSeek的新研究
让我们将目光转向DeepSeek的最新论文《Inference-Time Scaling for Generalist Reward Modeling》。这篇论文由DeepSeek与清华大学联合提出,核心亮点是SPCT方法(Self-Principled Critique Tuning),首次通过在线强化学习(RL)优化原则和批判生成,实现推理时扩展。
这项研究的主要动机在于解决现有奖励模型(Reward Model, RM)在通用领域中的局限性。尤其是在面对复杂、多样化任务时,RM往往表现出不足。为此,研究提出了两个关键挑战:一是通用RM需要具备灵活性(支持单响应、多响应评分)和准确性(跨领域高质量奖励);二是现有RM(如标量RM、半标量RM)在推理时扩展性较差,难以通过增加计算资源显著提升性能。
为应对这些挑战,DeepSeek与清华大学团队提出了SPCT方法,其核心技术点包括:
1. 生成式奖励模型(GRM)
GRM采用点式生成奖励模型(Pointwise GRM),通过生成文本形式的奖励(如critiques)而非单一标量值,支持灵活输入(单响应、多响应)和推理时扩展。其中,C是生成的critique,fextract从中提取分数。
2. SPCT方法
SPCT通过在线强化学习(RL)训练GRM,使其能动态生成高质量的原则(principles)和批判(critiques),从而提升奖励质量。整个过程分为两个阶段:拒绝式微调(Rejective Fine-Tuning)和基于规则的在线RL。
3. 推理时扩展技术
通过多次采样生成多样化的原则和批判,投票聚合最终奖励,扩展奖励空间。此外,训练一个辅助模型过滤低质量采样,进一步提升扩展效果。
基于上述方法,团队进行了多项测试。结果显示,在Reward Bench、PPE、RMB等基准上,DeepSeek-GRM-27B显著优于基线方法(如LLM-as-a-Judge、标量RM)。通过推理时扩展(32次采样),性能进一步提升(如Reward Bench准确率从86.0%提升至90.4%)。
总之,这项研究表明,推理时扩展在通用RM中的有效性优于训练时扩展。
奥特曼的新书预告
除了调整发布计划外,OpenAI还透露了两本新书的消息。一本是由Keach Hagey撰写的关于OpenAI创始人Sam Altman的传记,另一本则是Ashlee Vance撰写的关于OpenAI的深度报道。这两本书将进一步揭示OpenAI的发展历程和背后的故事。
本文来源: iFeng科技【阅读原文】
iFeng科技【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号