
中科大与华为联合推出生成式推荐大模型,并成功部署在国产昇腾NPU上。这一成果标志着生成式推荐技术迈入新阶段,同时公开了背后的认知研究。
第一段
在信息爆炸的时代,推荐系统已经成为日常生活中不可或缺的一部分。Meta率先提出了生成式推荐范式HSTU,将推荐参数扩展至万亿级别,取得了显著成效。近期,中科大与华为合作开发了一种新的推荐大模型部署方案,适用于多种场景。以下是报告中的亮点
1. 总结了推荐范式的发展历程,指出具备扩展定律的生成式推荐范式是未来趋势。
2. 复现并研究了不同架构的生成式推荐模型及其扩展定律,通过消融实验和参数分析,解析了HSTU的扩展定律来源,并赋予SASRec以可扩展性。
3. 验证了HSTU在复杂场景和排序任务中的表现及扩展性。
4. 团队展望并总结了未来的研究方向。
第二段
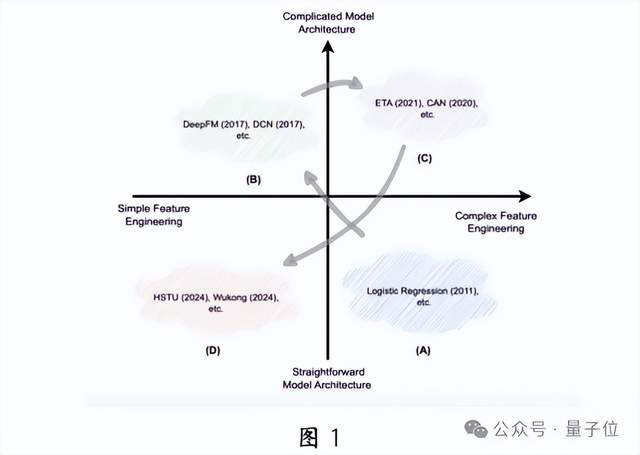
如图1所示,推荐系统的发展趋势是逐渐减少对手工设计特征工程和模型结构的依赖。在深度学习兴起之前,由于计算资源有限,人们倾向于使用手工设计的特征和简单模型(图1A)。随着深度学习的发展,研究者专注于复杂模型的设计,以更好地拟合用户偏好,并提升对GPU并行计算的利用率(图1B)。然而,随着深度学习能力的瓶颈,特征工程再次受到关注(图1C)。如今,大语言模型扩展定律的成功启发了推荐领域的研究者。通过增加模型深度和宽度,并结合大量数据,可以提升推荐效果(图1D),这种方法被称为推荐大模型。
第三段
为了评估生成式推荐大模型在不同架构下的扩展性,团队对比了HSTU、Llama、GPT和SASRec四种基于Transformer的架构。在三个公开数据集上,通过不同注意力模块数量下的性能表现进行分析(见表1)。结果显示,当模型参数较小时,各架构表现相似,且最优架构因数据集而异。然而,随着参数扩展,HSTU和Llama的性能显著提升,而GPT和SASRec的扩展性不足。尽管GPT在其他领域表现良好,但在推荐任务上未达预期。团队认为,这是因为GPT和SASRec的架构缺乏专为推荐任务设计的关键组件,无法有效利用扩展定律。
第四段
为了探究HSTU等生成式推荐模型的可扩展性来源,团队进行了消融实验,分别去除了HSTU中的关键组件:相对注意力偏移(RAB)、SiLU激活函数,以及特征交叉机制。实验结果(见表2)显示,单一模块的缺失并未显著影响模型的扩展性,但RAB的移除导致性能明显下降,表明其关键作用。
第五段
为了进一步分析赋予模型扩展定律的因素,团队比较了SASRec与扩展性良好的HSTU和Llama的区别,发现主要差异在于RAB和注意力模块内的残差连接方式。为验证这些差异是否为扩展性的关键,团队为SASRec引入了HSTU的RAB,并调整其注意力模块的实现方式。实验结果(见表3)显示,单独添加RAB或修改残差连接并未显著改善SASRec的扩展性。然而,当同时修改两个组件后,SASRec展现出良好的扩展性。这表明,残差连接模式与RAB的结合,为传统推荐模型赋予了扩展性,为未来推荐系统的扩展性探索提供了重要启示。
第六段
HSTU在多域、多行为和辅助信息等复杂场景中表现出色。以多域为例,HSTU在AMZ-MD的四个域中始终优于基线模型SASRec和C2DSR(见表4)。与单域独立训练的HSTU-single相比,多域联合训练的HSTU表现更佳,证明了多域联合建模的优势。表5显示,HSTU在多域行为数据上的扩展性显著,尤其在规模较小的场景如Digital Music和Video Games上。这表明HSTU在解决冷启动问题上具有潜力。
第七段
排序是推荐系统中重要的一环,团队深入探讨了生成式推荐模型在排序任务中的有效性和扩展性。正如表6所示,生成式推荐大模型在性能上显著优于DIN等传统推荐模型。尽管在小规模模型下,Llama的表现优于HSTU,但HSTU在扩展性方面更具优势,而Llama在扩展性上显得不足。
第八段
团队还研究了负采样率和评分网络架构对排序任务的影响,并进行了全面分析。此外,还探讨了缩减embedding维度对性能的影响。缩小embedding维度(表7)提升了小数据集ML-1M和AMZ-Books的性能,但在大数据集ML-20M上则有所下降。这表明,推荐大模型的扩展定律不仅受垂直扩展(注意力模块数量)影响,也受水平规模(embedding维度)影响。
第九段
在技术报告中,团队指出了数据工程、Tokenizer、训练推理效率等推荐大模型未来研究的潜力方向,这些方向将帮助解决当前的挑战并拓宽应用场景。
 量子位【阅读原文】
量子位【阅读原文】 相关文章

Copyright©2024 AI部落 AiClubs.cn AiBuluo.cn | AI工具大全 SiteMap XML 云标签 粤ICP备2024191087号